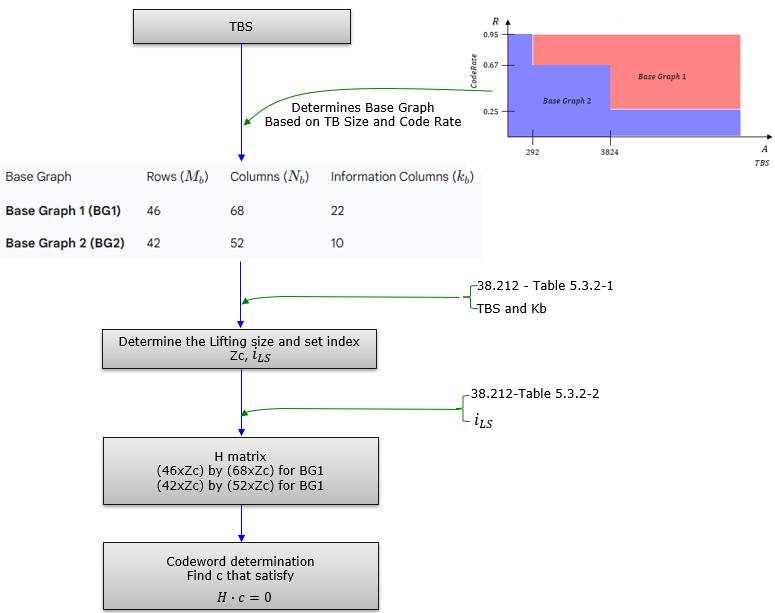
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
LDPC stands for "Low-Density Parity-Check". It's a method used in communication systems for encoding and decoding data to detect and correct errors. LDPC codes are a type of linear error-correcting code that has found extensive application in modern communication technologies. LDPC codes are a powerful and efficient method for error correction in digital communication systems, enabling reliable data transmission even in challenging and noisy environments. Here are some key points about LDPC:
This note is about LDPC with the perspective of the implementation in 5G/NR. Followings are the topics to be covered in this note
What I did to understand this ?As almost everybody would agree, LDPC is one of the most mysterious concepts in the NR specification. Even though the algorithm itself has existed for a very long time, I think there are not many people who have seriously tried to understand all the technical details behind it. Many people may know that NR uses LDPC for data channel coding. Many people may also know some keywords such as parity check matrix, Tanner graph, base graph, and lifting size. But connecting all of these into one clear picture is not easy. The following is not a dry technical description of LDPC. It is more like a record of how my understanding evolved step by step. It shows the phases I personally went through from the beginning until I reached my current level of understanding.
Phase 1 : Read 3GPP specification and try to decode the meaning out of the text. Of course, make NO SENSE AT ALL to meMy first approach was very simple. I opened the 3GPP specification and tried to understand LDPC directly from the text. At that time, I thought this would be the most reliable way. Since the specification is the final authority, I assumed that careful reading would eventually explain everything. But it did not work that way. The specification showed many tables, parameters, indexes, and pseudo-code like descriptions. I could see that they were describing some kind of channel coding procedure. But I could not build a clear picture in my mind. I already had some high-level understanding of channel coding. I knew basic ideas of convolutional coding, turbo coding, and block coding. But LDPC did not clearly fall into any of those familiar pictures for me. So the first confusion was very basic.
Why does the specification talk so much about matrices, base graphs, lifting size, and circular shifts ? At this stage, I was not really learning LDPC yet. I was mostly realizing that reading the specification alone was not enough. The specification tells us what to do. But it does not always tell us how to think about it. That was the first important lesson. Before decoding the LDPC algorithm, I first had to decode the way LDPC is described. Phase 2 : Read some background technical documents about the high level concept. I just picked some key words like 'Density', 'Parity', 'Graph' etc. But NO CONNECTED DOTS and No idea on how those concepts are associated with description in 3GPP specAfter failing to understand LDPC directly from the 3GPP specification, I changed my approach. I started reading background technical documents about LDPC. My expectation was that these documents would explain the high-level concept first, and then I would be able to go back to the 3GPP specification with a clearer picture. At this stage, I learned that LDPC stands for Low Density Parity Check Code. The name itself gave me some hints. Low density seemed to mean that the matrix is sparse. In other words, the matrix has many zeros and only a small number of ones. Parity was also a familiar word. I had seen parity in basic computer science, and also in communication technology such as RS232. So I thought I had at least some rough feeling about the meaning. But still, the full picture was not clear. Then I started seeing another important word again and again. One of the new term that caught my attention was Graph. Many LDPC explanations talked about graphs, nodes, edges, variable nodes, check nodes, and Tanner graphs. I could understand each word separately at a very shallow level. But I could not connect them together.
These words looked important, but they were still scattered words.
But there were no connected dots yet. I still could not see how these concepts were related to the actual description in the 3GPP specification. The specification talked about base graph, lifting size, shift values, and matrix expansion. The background documents talked about sparse matrices and Tanner graphs. I could sense that they were talking about the same thing from different angles. But I could not yet see the bridge between them. So Phase 2 was useful, but it was still frustrating. I collected many keywords. But I did not yet have one single mental picture that could connect all of them. Phase 3 : I came up with describing LDPC in a very simple math equation H c = 0. Then the question came up. In this equation, which one is known and which one is unknown ?After collecting many scattered keywords, I needed something simpler. So I learned a basic equation to describe the concept of LDPC. H c = 0 At first, this looked too simple. But this simple equation created the first real question for me.
This question was important because I realized that I was not even clear about the role of each element.
Then the picture started to become a little clearer.
This was a small step, but it was an important turning point. LDPC was no longer just a mysterious set of tables in the specification. It started to look like a question: : "Given a known rule H, can we find a codeword c that satisfies H c = 0, even when the received signal is noisy ?" Phase 4 : After leaning that H is known, I came up with question : How H matrix is constructed in 3GPP ?After I understood that H is known, the next question naturally came up. If H is known, where does it come from ? At first, I thought H may be given as one big matrix. In a textbook example, this is usually possible. The parity check matrix can be shown directly with zeros and ones. Then we can multiply H and c and check whether the result becomes zero. But NR LDPC is not that simple. The matrix is too large to write directly. Also, the matrix is not always the same. It changes depending on the transport block size, code rate, base graph, lifting size, and other parameters. So 3GPP does not simply say, “Here is the H matrix”. Instead, 3GPP describes how to construct H. This was another important turning point for me. H is known, but it is not stored as one fixed matrix. It is generated from a smaller structure. Then new questions started appearing.
At this stage, I realized that understanding LDPC in NR is not just about understanding the equation H c = 0. I also had to understand how NR creates H before using that equation.This is where the 3GPP tables started to look a little different. At first, those tables looked like random numbers. But later, I started to see them as construction instructions.
So Phase 4 changed my question again. The question was no longer only: What is H ? The new question became: How does 3GPP generate H from base graph, lifting size, and shift values ? Phase 5 : Constructing H matrix and c vector in code (javascript) for interactive simulation.This was the phase that gave me the clearest and most concrete understanding of 3GPP LDPC. Until this point, I had learned many concepts.
But still, the understanding was not fully concrete. Then I started implementing it in code. I tried to construct the H matrix by myself. I also created a c vector and tested whether the equation H c = 0 really works. This changed the feeling completely.
This was the moment when 3GPP LDPC started to look real to me. Before coding, I was mostly reading and imagining. After coding, I could actually see the structure being created. I used JavaScript because I wanted to make it interactive. I wanted to change parameters, generate the matrix, create vectors, and observe the result directly. This was not just an implementation exercise. It was a learning tool. By constructing H and c in code, I could finally connect the equation, the graph, and the 3GPP tables into one picture. If you are interested in what I've implemented using AI, check this out. LDPC in NRNR selected LDPC for the data channels (PDSCH and PUSCH ) due to its excellent performance and suitability for high-throughput, parallel processing. High Level Procedure of LDPC EncodingThis is about LDPC encoding process at the very highlevel based on my own understanding. This procedure shows that NR LDPC encoding is not a single fixed code. It is a structured family of codes. The encoder first treats the transport block as the input constraint. It then chooses the LDPC “template” that best fits that constraint, so the same physical mechanism can support very different TBS and code-rate points without redefining the whole parity-check matrix every time. The key idea is the separation between a small base graph and a large practical matrix. The base graph is the high-level structure that defines how variable nodes and check nodes are connected. Once the base graph is decided, the encoder does not build a brand-new design from scratch. It “lifts” the base graph by a lifting size, so each base-graph entry expands into a block made of circularly shifted identity matrices. This is how the final H matrix becomes large enough for real payload sizes while keeping the structure regular and implementation-friendly. After that, encoding becomes a constraint satisfaction problem in a very concrete form. You are looking for a codeword vector c that makes all parity checks pass, which is expressed as H · c = 0. So the whole flow can be viewed as: pick the right structural template for the target operating point, scale it up using a standardized lifting rule, and then generate parity bits so the resulting codeword satisfies the parity-check equations.
Now let me verbalize this diagram and it goes as follows
Core Principle - SparsitySimply put, the final goal of LDPC is to find out parity bits that satisfy the following equation: H × cT = 0 (modulo 2). This equation is the foundation of Low-Density Parity-Check (LDPC) codes, ensuring that a codeword c adheres to the parity-check constraints defined by the parity-check matrix H. The example in the image illustrates this principle through the encoding process, where the objective is to compute parity bits p given information bits s, such that the resulting codeword c satisfies this equation. Let’s elaborate on this as the core principle of LDPC, particularly in the context of 3GPP’s 5G NR, and explore its broader significance.
As a simple example, let's assume that we have a data s = [s1, s2, s3, s4] = [1, 0, 1, 1], meaning there are 4 bits of data (k = 4) and want to encode this to a codeword c = [s1, s2, s3, s4, p1, p2, p3, p4]. The final goal of LDPC is to find the p1, p2, p3, p4 to meet the condition H × cT = 0 (modulo 2). The complicated part of LDPC in real application (as in 5G) is about how to construct H matrix and How to decode the received LDPC data into original message. You're asking an interesting question about modifying the fundamental condition of LDPC codes from H × cT = 0 to H × cT = 1. Let’s explore why this change would not work in the context of LDPC codes, particularly as they are implemented in 3GPP’s 5G NR, and what the practical implications would be. Understanding the Standard Condition: H × cT = 0 In LDPC codes (and linear block codes in general), the condition H × cT = 0 (with operations in GF(2), i.e., modulo 2) ensures that the codeword c satisfies all parity-check equations defined by the parity-check matrix H. This condition is fundamental for several reasons:
This setup ensures that the code has a well-defined structure, enabling efficient encoding, decoding, and error correction. What Happens If We Change to H × cT = 1? If we redefine the condition to H × cT = 1, we’re fundamentally altering the rules of the code. Let’s break down why this wouldn’t work:
Could It Work in a Different Context? The condition H × cT = 1 resembles a non-homogeneous system, which isn’t typical for linear block codes but could be interpreted in other coding schemes:
Practical Implications in 3GPP In 3GPP’s 5G NR, LDPC codes rely on H × cT = 0 for:
Changing to H × cT = 1:
Summary The condition H × cT = 1 would not work for LDPC codes as defined in 3GPP or in standard practice because:
The H × cT = 0 condition is not arbitrary—it’s a cornerstone of linear block codes like LDPC, ensuring they are practical and effective for real-world communication systems. If you’d like to explore alternative coding schemes where non-homogeneous conditions might apply, let me know! LDPC Implementation in 5G - Structure
EncodingWhile LDPC codes are defined by the parity-check matrix H, encoding isn't as straightforward as with some other codes. 3GPP defines specific efficient encoding procedures based on the structured nature (QC-LDPC) of the codes. Essentially, given the information bits, the encoder calculates the necessary parity bits such that the resulting codeword (information bits + parity bits) satisfies all the parity-check equations defined by H (i.e., Rate MatchingWireless systems need to adapt the coding rate (ratio of information bits to total transmitted bits) based on channel conditions. LDPC in 3GPP uses a flexible rate matching procedure.
DecodingAt the receiver, an iterative decoding algorithm is used, typically the Belief Propagation (also known as Sum-Product) algorithm or a variation like Min-Sum.
What is QC-LDPC?QC-LDPC is a specific type of Low-Density Parity-Check (LDPC) code where the parity-check matrix (H) has a special, structured form. Instead of being an arbitrary sparse matrix, it's constructed from smaller square blocks, each of which is either a zero matrix or a circulant permutation matrix (CPM). Key Concepts1. LDPC Recap: Remember that LDPC codes are defined by a sparse parity-check matrix H. A vector 2. Cyclic Codes: In a strictly cyclic code, if you cyclically shift a valid codeword, you get another valid codeword. QC-LDPC is a generalization. 3. Circulant Permutation Matrix (CPM): This is the fundamental building block. A CPM is a square matrix (say, size Z x Z) where each row is a cyclic shift of the row above it. Crucially, each row and column has exactly one '1' and the rest '0's. They are essentially cyclically shifted identity matrices.
4. Quasi-Cyclic Structure: The "Quasi" part means the entire H matrix isn't necessarily cyclic, but it *is* composed of these CPM blocks (and zero blocks). If you divide the H matrix into ZxZ blocks, each block is a CPM or a zero matrix. How is the H Matrix Constructed?Often, a QC-LDPC matrix H is defined by: 1. A Lifting Factor (or Expansion Factor) Z: This defines the size (Z x Z) of the circulant blocks. 2. A Base Matrix (or Model Matrix) B: This is a smaller matrix whose entries tell you which CPM to place in the corresponding block position in the final H matrix.
If the Base Matrix B has dimensions ExampleLet's construct a small QC-LDPC matrix H. Choose Lifting Factor Z = 3. Define a Base Matrix B (size 2x4): Base Matrix refers to the matrix representation of what is called 'Base Graph' in 3GPP. B =
This is just an example of the simple Base Matrix. This is a Base Matrix (B) used to define the structure of a Quasi-Cyclic LDPC (QC-LDPC) parity-check matrix (H). This matrix doesn't directly contain message data. Instead, each number tells you how to construct a block within the larger, final parity-check matrix
Now, we need the 3x3 circulant permutation matrices corresponding to the shifts 0, 1, and 2, plus the 3x3 zero matrix:
Now, substitute these blocks into H according to the base matrix B:
Block Col 1 | Block Col 2 | Block Col 3 | Block Col 4
H = [
Writing this out fully: H =
This resulting H matrix is:
Why Use QC-LDPC?
In essence, QC-LDPC codes offer the excellent error-correction performance associated with LDPC codes while having a structure that makes them much more practical and efficient to implement in real-world communication systems. What is Lifting ?Lifting is the process used in QC-LDPC code construction to expand a small Base Graph (represented by a Base Matrix It works like this: You start with a Base Matrix
The result is the final parity-check matrix
Why is Lifting Needed?Lifting is a crucial technique used in modern communication standards (like 5G, Wi-Fi) for several important reasons:
In summary, lifting provides an elegant and efficient way to generate families of high-performing LDPC codes of various lengths from a small set of core designs (the Base Graphs), which is essential for the flexibility and efficiency required in modern communication systems. Lifting Table for 5G LDPCThe process of selecting the lifting size Zc in the context of LDPC is a critical step in the encoding procedure for 5G New Radio (NR)but it took me several years for me to understand the overall concept of the selection of a specific Listing size. The lifting size Zc determines how the base graph (a small, predefined matrix) is expanded into a larger parity-check matrix H that is used for encoding. Let’s break down the selection process based on the document.
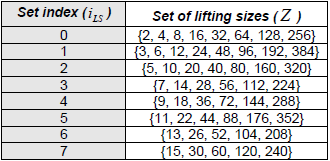
The lifting size Zc must be chosen such that the base graph can accommodate the input bit sequence of length K, and the resulting parity-check matrix H can be used for encoding. The selection of Zc is described in Step 1 and Step 2 of the encoding procedure in the document. Let’s go through these steps in detail: Step 1: Find the Set with Index iLS in Table 5.3.2-1 that Contains Zc
Step 2: For k = 22Zc to K-1, Perform the Following
Implicit Selection of Zc
Additional Details
Suppose K = 5000, and we’re using Base Graph 1 (since K ≤ 8448):
They are interrelated because they collectively define the structure and parameters needed to construct the parity-check matrix H, which is used for encoding data in the LDPC process. In short, the tables are tightly interrelated as part of the LDPC encoding process:
Here’s how they connect: Table 5.3.2-1 Provides the Lifting Size Zc, Which is Used by Tables 5.3.2-2 and 5.3.2-3
Tables 5.3.2-2 and 5.3.2-3 Depend on the Set Index iLS from Table 5.3.2-1
Tables 5.3.2-2 and 5.3.2-3 Define the Base Graphs, Which Are Lifted Using Zc
Base Graph Selection Affects Which Table (5.3.2-2 or 5.3.2-3) is Used
Summary of Interrelations
Flow of Dependency
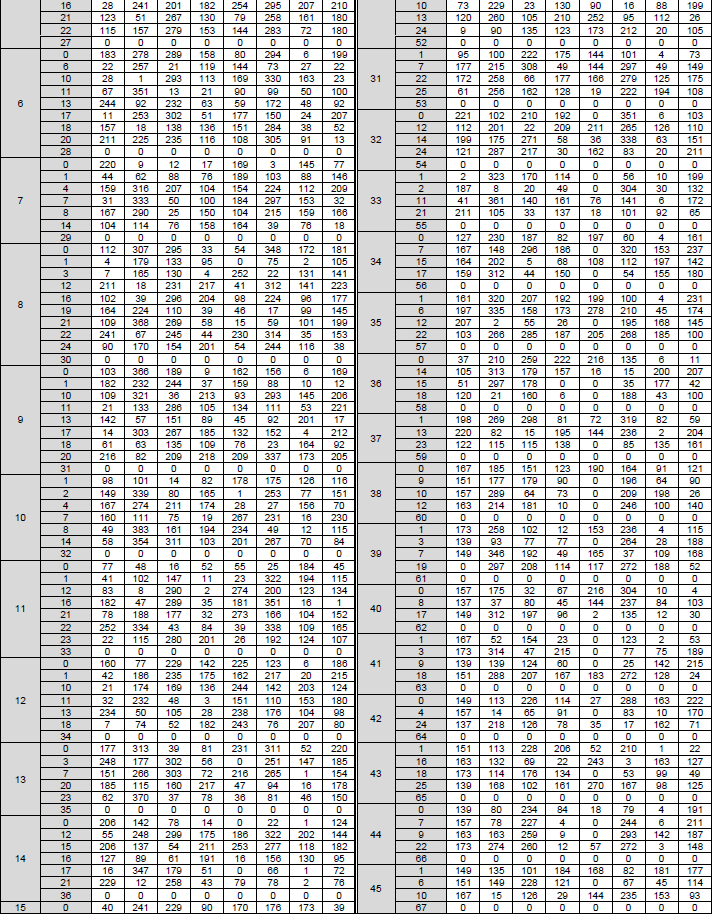
< 38.212-Table 5.3.2-1: Sets of LDPC lifting size Z > The structure, role of this table can be described as below :
NOTE : This table can be generated by the rule : base_Z x 2^j , where base_Z = the first elements in the set, j = [0 7]
In the 3GPP TS 38.212 standard, the lifting sizes are capped at 384. The table above follows the mathematical "doubling" rule strictly, but in practical 5G implementation, values exceeding 384 are typically not used for these specific sets. Removing the capped number, we can the following table which is same as 38.212 - Table 5.3.2-1
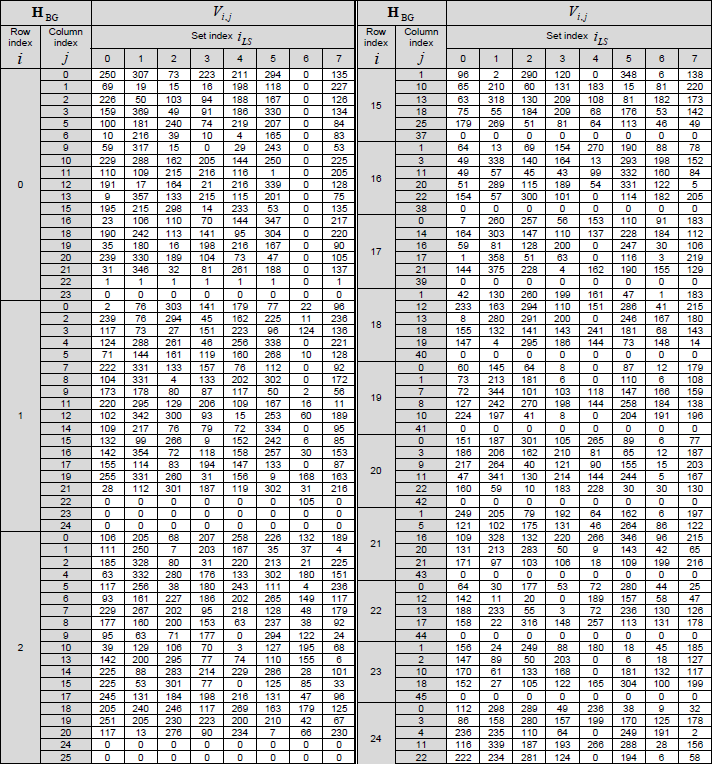
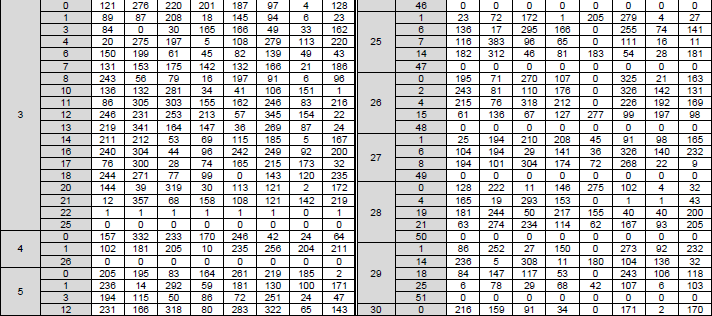
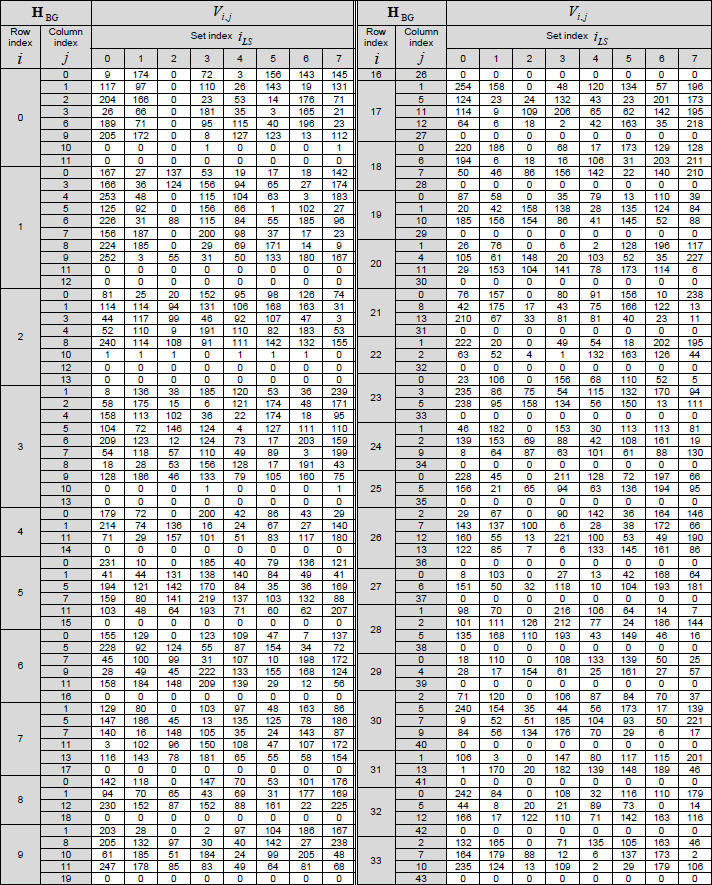
< 38.212-Table 5.3.2-2: LDPC base graph 1 (HBG) and its parity check matrices ( Vi,j) > The structure, role of this table can be described as below :
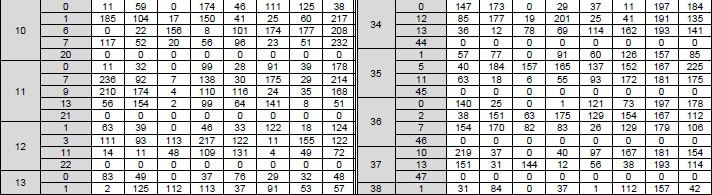
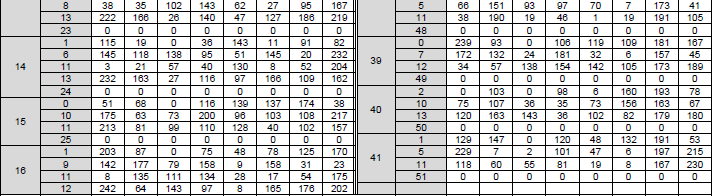
< 38.212-Table 5.3.2-3: LDPC base graph 2 (HBG) and its parity check matrices ( Vi,j) > The structure, role of this table can be described as below : Table 5.3.2-3: LDPC Base Graph 2 (HBG) and its Parity Check Matrices (Vi,j)
LDPC EncodingAt first, I tended to think of encoding as the less mysterious half of LDPC. The transmitter already knows the data, so it seemed that the encoder only had to add some parity bits and send the result. Compared with decoding, where the receiver has to struggle with noise and uncertainty, encoding looked almost too straightforward. But once I looked more carefully at NR LDPC, I realized that encoding also has its own structure. The encoder does not begin by writing one giant H matrix and blindly solving everything from there. It first decides how the transport block should be prepared, which base graph should be used, how large the lifted structure must become, where filler bits are needed, and how many coded bits can actually be transmitted over the available radio resource. So the key realization was this:
Following is the overall flow of LDPC encoding in the order used by a real transmitter.
Step 1 : Receive the transport block from higher layerThis is the true starting point of LDPC encoding. The transmitter does not begin with parity bits, matrices, or lifting sizes. It begins with a transport block from the higher layer. These are the real information bits that eventually have to survive the radio channel. This is already different from decoding. The receiver begins with uncertainty. The encoder begins with certainty. It already knows exactly what message it wants to protect. So the first question is very simple, but also very important: What is the actual information block that must be carried safely through the whole physical-layer process ? Once that block is known, the next question naturally appears. If the receiver later recovers some bits, how will it know whether they are really correct ? Conceptually, this is the payload that later becomes `A`, the transport-block size used throughout the NR processing chain.
Step 2 : Attach the transport-block CRCBefore the encoder starts adding LDPC parity, it first attaches a CRC to the transport block. At first, this can feel redundant. LDPC already has parity checks, so why add another check before encoding ? The reason is that the two kinds of checks serve different purposes.
This distinction matters. A codeword may satisfy the LDPC structure and still not be the originally transmitted message. CRC gives the receiver a final integrity test outside the LDPC graph itself. So at this stage, the encoder is asking: How can I attach a small signature to the information block so the receiver can later judge whether the recovered result is truly valid ? Now the block has become slightly larger. The next question is whether it still fits comfortably into one LDPC code block. The receiver-side implementation reconstructs the same TB-CRC length from the transport-block size.
Step 3 : Segment the block if it is too largeNow the encoder has a block containing the original information plus the transport-block CRC. But one LDPC code block cannot be allowed to grow without limit. If the block is too large, the complexity of encoding and decoding would also become too large. So NR asks a practical question before moving further: Can this whole block be handled as one LDPC code block, or should it be divided into smaller pieces ? If the block is small enough, it remains as one code block. If it is too large, it is segmented. This keeps the LDPC operation manageable and lets each part be processed with a bounded code-block size. So segmentation is not mainly about changing the information. It is about fitting the information into a structure that the LDPC machinery can handle efficiently. But once the block is split into several pieces, another question appears. If one piece is decoded incorrectly later, how will the receiver know which piece failed ? The current Python receiver computes the same segmentation parameters that an encoder would have used.
Step 4 : Attach code-block CRC when segmentation is usedIf segmentation produced more than one code block, each code block receives its own CRC. This is easy to overlook because the transport block already had a CRC. But after segmentation, each code block becomes a separate unit for LDPC processing. If one of them fails while the others succeed, the receiver benefits from knowing that at the code-block level. So the encoder adds a local check to each segmented block. This gives the receiver two levels of confidence later:
The question at this stage is: If the transport block has been split apart, how can each piece carry enough self-checking information to be verified on its own ? Now the information has been prepared. The next question is no longer about CRC. It is about which LDPC structure should carry this block. In the receiver, the corresponding code-block CRC is checked only when more than one code block exists.
Step 5 : Select the proper NR LDPC base graphNow the encoder has to choose the LDPC family itself. NR does not use one single fixed LDPC matrix for every situation. Instead, it provides two standard base graphs. One is better suited to larger blocks and higher code rates. The other is better suited to smaller blocks or lower code rates. This is one of the most important NR-specific decisions. The encoder is not yet constructing the full H matrix. It is first choosing the small structural template from which the final matrix will later be created. So the encoder asks: Given this block size and this operating point, which standard LDPC skeleton should I start from ? Once the base graph is chosen, the rough shape of the code is known. But it is still only a small template. The next question is: how large should that template become ? The decoder repeats the same selection rule so both sides agree on the LDPC structure.
Step 6 : Determine the lifting size ZcThe selected base graph is still too small to encode a real code block directly. It is more like a blueprint than a finished building. The lifting size Zc tells the encoder how much that blueprint should be expanded. Every valid base-graph entry becomes a Zc by Zc block, and the final LDPC structure scales with that choice. The encoder cannot choose any arbitrary value. NR defines a set of allowed lifting sizes, and the encoder must select one large enough to hold the required information bits. So the question becomes: How large must the LDPC structure become so that this code block fits, while still using one of the allowed standardized lifting sizes ? After this choice, the encoder knows the required LDPC input size. But sometimes the real information block is still slightly smaller than that size. Then one more adjustment is needed. The Python receiver recovers the same lifting size from the same allowed set.
Step 7 : Insert filler bits if the LDPC input is larger than the real information blockOnce the LDPC input size is fixed, the encoder may discover a small mismatch. The chosen structure may have room for more information positions than the real code block actually needs. The encoder cannot leave those positions undefined. So it inserts filler bits into the unused positions, usually known zeros. These filler bits are not user data. They are more like temporary placeholders that let the real information fit neatly into the rigid LDPC input shape selected by the standard. This step answers the question: If the standard LDPC input structure is slightly larger than my real information block, what should occupy the unused positions ? Now every required information-side position has a defined value. The next question is about the rule that the entire future codeword must obey. The receiver later identifies these same filler locations and treats them as known zeros.
Step 8 : Construct or identify the parity-check structure HWith the base graph and lifting size fixed, the encoder now knows the parity-check structure H that defines the code. This is a subtle but important shift. Until now, the encoder was preparing the information block. From this point onward, it starts preparing the mathematical rule that the full codeword must satisfy. In practice, NR does not need to store one huge dense matrix. The quasi-cyclic structure lets the implementation describe H compactly from the base graph, shift values, and lifting size. But conceptually, the meaning is the same: H tells which bit positions participate in which parity equations. So the encoder is now asking: What exact parity-check structure must the final codeword satisfy ? Once H is known, there is still a practical question left. Where do the original information bits go inside the codeword that must satisfy H c = 0 ? The receiver-side implementation reconstructs the same graph structure from the NR parameters.
Inside this function, the implementation first loads the selected base-graph table for the chosen lifting-set index. Then it walks through every base-graph row and column. A value smaller than 0 means there is no connection at that location. A valid shift value means that one base-graph entry must become a whole shifted circulant pattern after lifting. So the code does not build one giant dense H matrix cell by cell. Instead, it directly creates the graph connections that the decoder will need later.
In other words, the quasi-cyclic matrix description is converted directly into a Tanner-graph representation.
After that first pass, the implementation builds the reverse lookup for variable nodes:
This is also where the standard table becomes real code. The values from 38.212 Table 5.3.2-3, the LDPC Base Graph 2 table, are stored in the project as a machine-readable file:
The implementation does not copy the whole 3GPP table directly into the Python source file. Instead, `_load_bg2(i_ls)` reads this CSV file and rebuilds the BG2 matrix for the selected lifting-set index.
The meaning of this is very direct.
So the flow is:
This is a very important point. The standard table is not only a reference table for documentation. In a real implementation, it is the compact description from which the actual LDPC graph is reconstructed. Step 9 : Place the information bits into the systematic part of the codewordNR LDPC is systematic. That means the original information bits are placed directly into designated positions of the codeword rather than being hidden inside a completely transformed representation. This is helpful because it gives the codeword a clear division:
The filler bits, if any, occupy part of the systematic side as known placeholders. The true payload bits remain distinguishable from them. So at this stage, the encoder asks: Which positions of the future codeword should contain the original information, before I solve for the parity part ? Now the known part of the codeword is placed. The unknown part is the parity portion. This leads directly to the heart of encoding. The decoder later takes the first information positions back out after decoding.
Step 10 : Generate parity bits so that H c = 0This is the point where LDPC encoding truly earns its name. The encoder already knows the information bits and the parity-check structure. What remains is to choose parity bits so that the complete codeword satisfies: H c = 0 Unlike decoding, there is no uncertainty here. The encoder is not guessing which codeword was sent. It is deliberately constructing one valid codeword from known information bits. The conceptual question is: Given the information bits already fixed in the systematic positions, what parity bits must be chosen so that every LDPC parity equation is satisfied ? Once those parity bits are found, the codeword is mathematically valid. But the encoder is not finished, because a valid mother codeword is not always the exact sequence that will be transmitted over the radio. The current project is receiver-side, so it does not contain a production LDPC encoder. This small fragment shows the condition the encoder must satisfy.
Step 11 : Form the LDPC code blockAfter the parity bits are generated, the encoder now has a complete LDPC code block. This is an important milestone. Earlier steps prepared information, selected structure, and solved parity constraints. Now all of those decisions have become one concrete codeword that satisfies H c = 0. The code block contains:
At first, it may seem that this code block should simply be transmitted as it is. But NR still has one more reality to deal with: the radio resource may not have room, or may not need, every bit of the mother codeword. So the next question is: Which parts of this valid mother codeword are actually prepared for transmission ? The receiver later refers to the corresponding lengths as K and N.
Step 12 : Puncture the first 2 Zc bits of the mother codeIn NR LDPC, the transmitted stream does not begin by sending every bit of the mother codeword. The first 2·Zc bits are punctured. In other words, they belong to the underlying mother-code structure but are not transmitted over the air. The receiver later knows that these positions existed even though no direct channel observation was received for them. This is one of those details that makes NR LDPC feel less like a textbook block code and more like a practical radio system. The code structure and the transmitted sequence are related, but not identical. So the encoder asks: Which mother-code positions are structurally present, but intentionally not sent as part of the transmitted bit stream ? After puncturing, the encoder still may have more coded bits than the resource allocation can carry. Now it needs a controlled way to choose which coded bits will go out in this transmission. The decoder mirrors this by inserting neutral LLRs at those punctured positions before belief propagation.
Step 13 : Select bits from the circular buffer according to redundancy versionThe encoder now enters the circular-buffer view of rate matching. The coded bits are treated as positions in a circular buffer. Depending on the redundancy version, the encoder begins reading from a different starting point. This is how different HARQ transmissions can emphasize different portions of the same underlying codeword. This is not random selection. It is a standardized pattern that gives the receiver a predictable way to combine information across transmissions later. The question at this point is: From which position in the circular buffer should this particular transmission begin selecting coded bits ? Once the starting point is known, one more practical constraint remains: exactly how many coded bits are needed for the scheduled radio resource ? The receiver computes the same starting point `k0` when reversing rate matching.
Step 14 : Repeat or omit bits to match the available radio resourceThe available physical resource determines the target number of coded bits that can be transmitted. If fewer bits are needed than the mother structure contains, some bits are not selected in this transmission. If more bits are needed, the circular buffer may wrap and some coded bits may be repeated. This is the reason the word rate matching is so appropriate. The encoder is matching the coded output to the actual resource situation. So the encoder asks: How do I reshape the protected LDPC output so that its length exactly matches the number of coded bits the radio allocation can carry ? Now the right number of bits has been chosen. But before mapping them into modulation symbols, NR still rearranges their order in a specific way. The receiver computes `E` for each code block and later rebuilds the buffer from that number of received bits.
Step 15 : Interleave the selected coded bitsThe selected coded bits are now interleaved. Interleaving can look like a simple shuffling step, but it has a purpose. It arranges the bit stream so that the different bit positions within a modulation symbol receive coded bits in the NR-defined order. This makes the later modulation mapping compatible with the transmission format expected by the receiver. It is useful to think of this as another alignment step. Earlier, the encoder aligned the information with the LDPC structure. Now it aligns the coded output with the modulation structure. The key question becomes: Before I group bits into symbols, in what order should the selected coded bits be arranged ? After the order is settled, the bits are still too regular to transmit directly. The encoder next applies scrambling. The receiver later undoes this interleaving before LDPC decoding.
Step 16 : Scramble the coded bit streamNow the encoder scrambles the coded bit stream. Scrambling does not replace LDPC coding, and it is not a second error-correcting code. Its role is different. It prevents undesirable long patterns, helps randomize the transmitted sequence, and ties the transmission to parameters such as the RNTI and cell identity. This is another good example of how the physical layer combines several kinds of processing that serve different purposes:
The encoder is now asking: How can I make the transmitted coded sequence less pattern-prone while keeping it perfectly reversible at the receiver ? After scrambling, the data is finally ready to leave the bit domain and become constellation symbols. The receiver reverses this by sign-flipping LLRs with the same Gold sequence.
Step 17 : Map bits to modulation symbolsOnly now does the encoder perform modulation mapping. Several bits are grouped together and mapped onto one complex-valued constellation point. With QPSK, each symbol carries two bits. With 16QAM, each symbol carries four bits. With 64QAM, each symbol carries six bits. This is an important transition. Up to this point, the encoder has been working with abstract binary sequences. After this step, the protected information becomes actual transmit symbols that will occupy the radio resource grid. So the question changes form: How should this final coded bit stream be represented as physical symbols that the transmitter can place onto the air interface ? Once symbols exist, the encoder-side construction is essentially complete. The next step is no longer about creating more structure. It is about sending the result into the channel. For the present SIB1 path, the receiver uses a QPSK demapper because SIB1 decoding here is QPSK-based.
Step 18 : Transmit the encoded symbols over the airAt the end of encoding, the transport block has gone through a long transformation.
The transmitter has now finished the construction process. What leaves the transmitter is no longer just the original information block. It is a carefully prepared waveform designed to survive the wireless channel. This naturally leads to the final encoding-side question: Now that the codeword has been constructed and mapped into symbols, what happens when the channel begins to distort it ? That is exactly where the next section begins. Encoding ends with a deliberately constructed signal. Decoding begins with an uncertain observation of that signal after the real world has had its effect on it. The decoder begins later from the equalized received symbols `eq_data` rather than from the original clean bits.
LDPC DecodingAt first, I thought LDPC decoding would be a simple reverse process of LDPC encoding. In many technologies, this kind of thinking works reasonably well. If the transmitter performs a certain sequence of operations, the receiver often performs the reverse sequence to recover the original data. So I naturally expected LDPC decoding to work in the same way. The encoder creates parity bits from information bits, so I thought the decoder would somehow reverse that operation and directly recover the original information bits. But LDPC decoding does not really work that way. The receiver does not receive a clean encoded bit sequence. It receives noisy, uncertain channel observations. Because of this, decoding cannot be just an inverse calculation. The decoder has to make a best guess from unreliable evidence. It knows the LDPC structure, but it does not know which received bits are correct and which ones are wrong. This is where LDPC decoding becomes interesting. Instead of reversing the encoder step by step, the decoder uses the parity check matrix H as a rule book. It asks whether the current candidate codeword satisfies H c = 0. If not, it does not simply flip bits one by one. It lets variable nodes and check nodes exchange soft messages through the Tanner graph. Each iteration refines the belief about every bit by combining the channel evidence and the parity constraints. So the key realization was this:
If the parity checks pass, the LDPC part looks successful. But the final trust comes from CRC. If CRC passes, the decoded transport block is delivered. If not, HARQ gives the receiver another chance by combining more soft information from retransmission. So the real beauty of LDPC decoding is not just in the matrix or the graph. It is in the way uncertain channel evidence and strict parity structure keep interacting until the receiver either finds a consistent message or admits that it needs more evidence. Following is the overall flow of LDPC decoding in the order used by a real receiver.
Step 1 : Receive the noisy channel symbolsThis is the very first input to the LDPC decoding process. At the transmitter side, the original transport block is encoded by LDPC. Then the encoded bits are rate matched, scrambled, modulated, and transmitted over the air. But the receiver does not receive clean bits. The receiver receives radio signals that have passed through the wireless channel. So the received signal may be distorted by many things.
So at this point, the receiver is not seeing something like this: 0 1 1 0 1 0 0 1 Instead, it receives complex-valued symbols. For example, in QPSK, the transmitter may send one constellation point representing two bits. But at the receiver, that point may not appear exactly at the ideal position. It may be shifted, rotated, or blurred. So the receiver may see something like this: 0.72 + j0.65 -0.81 + j0.54 0.12 - j0.95 -0.40 - j0.30 These are not bits yet.They are noisy channel symbols. This is an important point. LDPC decoding does not start from perfect 0 and 1 values. It starts from uncertain information. The receiver first has to ask:
If the receiver immediately converts every received symbol into hard bits, a lot of useful information is lost. For example, a received symbol very close to the ideal 0 position and another symbol barely on the 0 side would both become 0. But their reliability is very different. LDPC decoding needs this reliability information. So in this first step, the receiver simply collects the noisy received symbols from the channel. These symbols are still analog-like or complex-valued digital samples after RF/baseband processing. They are not yet the final decoded bits. The main question at this stage is: What did the channel give us, and how uncertain is it ? In the Python implementation, this input is the equalized PDSCH symbol stream passed into the SIB1 decoder. At this point, the values are still complex-valued channel observations, not decoded bits.
Step 2 : Demodulate the received symbolsAfter the receiver gets the noisy channel symbols, the next step is demodulation. The received symbols are still complex values. They are not bits yet. For example, in QPSK, each transmitted symbol represents 2 bits. In 16QAM, each symbol represents 4 bits. In 64QAM, each symbol represents 6 bits. In 256QAM, each symbol represents 8 bits. So the receiver has to map each received constellation point back to the possible bit values. But there is an important point here. The receiver should not simply say:
That would be hard demodulation. For LDPC decoding, this is usually not enough. Instead, the receiver tries to estimate how likely each bit is to be 0 or 1. For example, assume QPSK. If the received point is very close to the ideal constellation point for 00, then the receiver can be highly confident that the bits are 00. But if the received point is near the boundary between 00 and 01, the receiver should not be too confident. It may say:
This is the key idea of soft demodulation. The demodulator does not just produce decoded bits. It produces reliability information for each bit. This reliability information later becomes LLR values. So demodulation is the bridge between the noisy constellation symbols and the LDPC decoder. The channel gives us distorted symbols. The demodulator converts those symbols into bit-level confidence. At this stage, the receiver is not yet correcting errors. It is only preparing useful soft information for the LDPC decoder. The important question here is: For each received symbol, how strongly does it suggest each bit is 0 or 1 ? In the implementation, demodulation is performed by the QPSK soft demapper. It converts each complex symbol into two bit-level soft values rather than making only a hard 0 or 1 decision.
Step 3 : Calculate soft values for each coded bitAfter demodulation, the receiver does not want to produce only hard bit values like 0 or 1. It wants to produce soft values. A soft value means:
How confident is the receiver about this judgment ? This is very important for LDPC. LDPC decoding works much better when it knows not only the estimated bit value, but also the reliability of that bit. For example, assume the receiver has two received bits.
If we use hard decision, both become 0. But from the LDPC decoder point of view, these two bits are very different.
This difference matters a lot. During LDPC decoding, the decoder may decide that the weak 0 should actually be flipped to 1 if the parity check constraints suggest so. But it will be more reluctant to change the strong 0 because the channel observation was more confident. So the soft value is like the first opinion from the channel. It does not say:
It says something more like:
In practical systems, this soft value is usually represented as an LLR, Log-Likelihood Ratio. But before going into the exact LLR formula, the important idea is simple. The receiver assigns a reliability value to every coded bit. This means every bit entering the LDPC decoder carries two kinds of information.
So this step is not yet LDPC decoding itself. It is preparation for LDPC decoding. The main question at this stage is: For each coded bit, how much should the decoder trust the channel observation ? The soft values are formed from the real and imaginary parts of each QPSK symbol. Their sign tells the likely bit direction, and their magnitude carries the confidence.
The current SIB1 implementation only needs QPSK. If the same receiver were extended to higher-order modulation such as 16QAM or 64QAM, the demapper would no longer produce only two LLRs from the real and imaginary axes. It would evaluate every constellation point and generate one LLR for each bit position carried by the symbol.
Step 4 : Generate LLR values for all received bitsNow the receiver converts the soft information into a more formal value. This value is called LLR. LLR means Log-Likelihood Ratio. The basic idea is simple. For each received coded bit, the receiver asks:
So LLR is not just a bit value. It is a signed confidence value. In many common conventions:
So the following values have different meanings:
This is why LLR is much more useful than hard bits. A hard bit can only say 0 or 1. But LLR can say how strongly the receiver believes that 0 or 1 is correct. For example, two received bits may both be decided as 0 by hard decision. But their LLR values may be very different. One may be +9. Another may be +0.3. To the LDPC decoder, these are not the same. The +9 bit is very reliable. The +0.3 bit is weak and suspicious. During iterative decoding, the weak bit can be changed more easily if the parity check equations disagree with it. But the strong bit will need much stronger evidence before it is changed. This is the key point.
From this point, LDPC decoding can start using both pieces of information:
The main question at this stage is: For every bit, how strongly does the received signal support 0 or 1 ? The decoder records the LLR stream and even keeps simple diagnostics such as minimum, maximum, and mean absolute LLR so the receiver can inspect the quality of the soft information.
Step 5 : Select the proper NR LDPC base graphBefore constructing the LDPC parity check matrix H, the receiver has to know which base graph is used. In NR LDPC, there are two base graphs.
This is one of the first NR-specific parts of LDPC. The receiver does not freely choose any random LDPC matrix. It follows the same rule as the transmitter. Based on the transport block size and code rate, both transmitter and receiver select the same base graph. In simple terms:
This matters because the base graph is the seed structure of the whole LDPC matrix. At this point, the receiver is not yet building the full H matrix. It first asks:
In NR, this decision is made from parameters such as: Transport block size
A simplified rule is like this:
More specifically, NR commonly selects Base Graph 2 when the transport block is very small, or when the transport block is not large and the code rate is not high, or when the code rate is very low. Otherwise, Base Graph 1 is used. This step is important because everything after this depends on the selected base graph.
So the base graph is like the skeleton of the LDPC code. But it is not yet the full body. The full H matrix is created later by expanding this base graph using the lifting size and shift values. The important question at this stage is: Before building the huge LDPC matrix, which small standard-defined structure should be used as the starting point ? The base graph is selected from the transport block size and code rate using the same rule as the transmitter. For SIB1-sized blocks, this commonly leads to Base Graph 2.
Step 6 : Determine the lifting size ZcAfter selecting the base graph, the next step is to determine the lifting size. The lifting size is usually written as Zc. This is one of the most important parameters in NR LDPC. At first, Zc may look like just another number in the specification. But conceptually, it has a very important role. The base graph itself is only a small matrix. It is not the final parity check matrix H. Each entry in the base graph must be expanded into a bigger block. The size of that block is Zc by Zc. So Zc tells how much the base graph should be expanded.
This is why it is called lifting size. It lifts a small base graph into a large real LDPC matrix. For example, if one entry in the base graph is valid, it may become a Zc x Zc shifted identity matrix. If one entry in the base graph is -1, it becomes a Zc x Zc all-zero matrix. So the base graph defines the rough connection pattern. Zc defines the scale of expansion. The receiver determines Zc using the same rule as the transmitter. It is mainly related to the code block size after transport block segmentation and the selected base graph. The receiver has to choose a Zc large enough to fit the required number of information bits in the LDPC code block. In NR, Zc is not any arbitrary number. It must be selected from a predefined set of lifting sizes in the specification. This is why the receiver does not just calculate any convenient value. It selects one allowed Zc value that matches the code block requirement. This step is important because once Zc is chosen, the real size of the LDPC structure becomes fixed.
So at this stage, the receiver is asking: How large should the base graph be expanded so that it can support this code block ? This is the role of Zc. It is the scaling factor that turns the small NR base graph into the actual LDPC parity check structure used for decoding. After the base graph is known, the implementation chooses the smallest allowed lifting size that can hold the code-block information bits.
Step 7 : Undo bit interleaving if appliedBefore transmission, the encoded bits may be interleaved. Interleaving means the bit order is rearranged. At first, this may look like a simple permutation. But the reason is important. Wireless errors are often not evenly spread. Sometimes a group of nearby symbols may be badly affected by fading, interference, or noise. If the bits are transmitted in the original order, this may create a burst of errors in one part of the codeword. That is not good for decoding. LDPC decoding usually works better when errors are spread out rather than concentrated in one small region. So the transmitter may interleave the bits before modulation or transmission. It spreads nearby coded bits across different modulation positions or resource locations. At the receiver side, this rearrangement has to be reversed before LDPC decoding can really begin. The receiver must put the bits back into the order expected by the LDPC structure. This is the role of deinterleaving. Conceptually, the receiver asks: The transmitter shuffled the coded bits before sending them. How do I put them back into the original LDPC codeword order ? This matters because the parity check matrix H assumes a specific bit order. Variable node 0 means one specific coded bit. Variable node 1 means another specific coded bit. If the LLR values are attached to the wrong variable nodes, the decoder will check the wrong parity relationships. So deinterleaving is not just cosmetic. It restores the correct mapping between received soft bits and LDPC variable nodes. The important point is this: LDPC decoding does not only need reliable LLR values. It also needs those LLR values to be placed at the correct bit positions. So this step makes sure the soft information from the channel is aligned with the structure that the LDPC decoder will use next. In the real receiver flow, the bit interleaver is undone before LDPC decoding so the LLRs return to the codeword-related order expected by rate recovery.
Step 8 : Remove rate-matching effects before LDPC decodingBefore LDPC decoding can begin, the receiver still has to remember one thing. The bits transmitted over the air may not be exactly the same as the full LDPC encoded bit sequence. Before transmission, NR performs rate matching. This means the transmitter may select, repeat, or skip some encoded bits so that the number of transmitted bits matches the available radio resources. The LDPC encoder may create a codeword of a certain size. But the PDSCH or PUSCH allocation may allow only a certain number of coded bits to be transmitted. So the transmitter adjusts the encoded bit stream through rate matching. At the receiver side, this effect must be handled in the reverse direction. This is often called rate dematching. The receiver has to reconstruct the proper LDPC decoder input from the received soft bits. Some bits may have been punctured. That means they were not transmitted. For those bits, the receiver has no real channel observation, so their LLR may be filled with neutral values. Some bits may have been repeated. In that case, the receiver may combine the repeated soft values. Some bits may have been selected from a circular buffer. So the receiver has to put the received LLR values back into the correct positions before LDPC decoding. Conceptually, this step asks: The transmitter changed the encoded bit stream to fit the radio resource. How do I undo that mapping so the LDPC decoder receives the bits in the expected codeword positions ? This is important because LDPC decoding depends on bit positions. The H matrix assumes that each coded bit is in a specific position. If the received LLRs are placed in the wrong positions, the parity check equations no longer match the intended code structure. So rate dematching is not just a bit rearrangement. It is the step that restores the connection between the received soft bits and the LDPC codeword structure. Without this step, the decoder may be using correct LLR values, but attached to the wrong variable nodes. And that would make the Tanner graph conversation meaningless. The implementation then performs rate recovery. It places the received LLRs back into the NR circular buffer, combines repetitions, and skips filler positions.
Step 9 : Place known filler-bit values into the decoder input if neededThere is one more practical detail before iterative decoding starts. In NR LDPC, the original information block does not always fill the whole LDPC input structure. When the real information bits are not enough, filler bits are inserted during encoding so that the block fits the required LDPC size. These filler bits are not unknown user data. They are known positions, usually treated as zero. So at the receiver side, they should not be treated like ordinary received bits with ordinary uncertainty. Instead, once the receiver knows the code block structure, it can place very strong known values at the filler positions before LDPC decoding begins.
This helps the LDPC decoder because those positions do not need to be guessed in the same way as transmitted bits. They are already known parts of the structure. So before the Tanner graph conversation starts, the receiver makes sure of one more thing: Which positions are real received soft bits, and which positions are known filler bits that should already be fixed in the decoder input ? Known filler positions are not left as unknown received bits. They are clamped to a strong known-zero LLR before the iterative decoder starts.
Step 10 : Construct or identify the parity check matrix HAfter the base graph and lifting size Zc are decided, the receiver can now construct the real parity check matrix H. This is the matrix used by the LDPC decoder. But in NR, H is usually not stored as one huge matrix full of 0 and 1 values. That would be too large and inefficient. Instead, the receiver constructs H from the standard-defined base graph and lifting size. The base graph gives the small structure.
This is the key idea. The final H matrix is not arbitrary. It is a structured matrix.
At this point, the receiver knows the full parity check structure.
This does not mean the receiver already knows the correct codeword c. It only means the receiver knows the rule that the correct codeword must satisfy. This is why H is so important. The LLR values came from the noisy channel. But H comes from the standard-defined LDPC structure.
LDPC decoding happens by combining these two. The receiver asks: Given these unreliable LLR values from the channel, can I find a codeword that satisfies the fixed parity check matrix H ? So this step is where the abstract 3GPP tables become the actual decoding structure. The runtime decoder does not need to store one huge dense matrix. It reconstructs the needed parity-check structure from the standard-defined base graph and lifting parameters.
Step 11 : Build the Tanner graph from HAfter the parity check matrix H is constructed or identified, the same structure can be represented as a graph. This graph is called a Tanner graph. At first, this may sound like a completely new object. But it is not really new. The Tanner graph is another way of drawing the same information contained in H. The matrix H tells which coded bits are involved in which parity check equations. The Tanner graph shows the same relationship visually. In the Tanner graph, there are two types of nodes.
Now the question is: How do we know which variable node is connected to which check node ? The answer comes directly from H.
For example, if H row 3 column 10 is 1, it means coded bit 10 participates in parity check equation 3. So in the Tanner graph, variable node 10 is connected to check node 3. This is the important point.
The received LLR values will be attached to the variable nodes later. But they do not define the graph structure. So H defines the skeleton. The Tanner graph is the graphical form of that skeleton. Once this graph is built, LDPC decoding can be understood as message passing on this graph.
Through this repeated exchange, each bit gradually receives opinions from the channel and from the parity check constraints. So this step is where the matrix view changes into a communication view.
This is why the Tanner graph is important. It gives a concrete picture of how iterative LDPC decoding happens. The main question at this stage is: How can the fixed parity check matrix H be converted into a network of bit nodes and check nodes, so that decoding can be done by passing messages through that network ? The Tanner graph is represented directly by edge lists: which edges belong to each check node, which edges belong to each variable node, and which variable node each edge touches.
Step 12 : Initialize variable nodes with the prepared LLR valuesNow the Tanner graph is ready.
But the graph still does not know what the receiver actually received from the channel. This is where the prepared LLR values come in. They are the received soft values after the receiver has put them back into the proper LDPC positions. Each variable node represents one coded bit. So each variable node is initialized with the prepared LLR value for that coded-bit position. This LLR is the first belief about that bit.
This is an important moment in LDPC decoding. Before this step, the Tanner graph was only a structure. It was like a wiring diagram. After this step, the graph gets real information from the received signal. Each bit node now has its own initial opinion.
The LDPC decoder does not know which ones are wrong yet. It only knows two things.
Then the decoding process starts asking a deeper question.
The LLR values are not final decisions. They are only starting beliefs. The later message passing process will refine these beliefs by using the parity constraints from the Tanner graph. So at this stage, the receiver is basically saying: This is what the channel seems to tell me about each bit. Now let the parity check structure examine whether these beliefs make sense together. Once the graph exists, the prepared channel LLRs are attached to the codeword positions. The first 2?Zc mother-code bits are punctured, so they begin with neutral LLR values.
Step 13 : Initialize check node messagesNow each variable node already has its initial LLR value. This means every coded bit has its first opinion from the channel. But the check nodes still have not said anything yet. A check node represents one parity check equation. It does not represent a bit by itself. It represents a rule that several bits must satisfy together. For example, a check node may be connected to several variable nodes. This means those bits are involved in the same parity check equation. The check node will later ask: Do these connected bits satisfy the parity rule ? If not, which bit is suspicious ? But before iterative decoding starts, the messages on the graph must be initialized. Usually, the first messages from variable nodes to check nodes are initialized from the channel LLR values. In other words, each variable node sends its initial channel belief to all connected check nodes. At the very beginning, the check node has no extra information yet.
So this step is like preparing the first round of conversation. The variable nodes say: This is what the channel told me about my bit. Then the check nodes prepare to respond by checking whether those bit beliefs are consistent with their parity rule. This is an important transition point. Until now, each bit was judged mostly alone. Each LLR came from its own received symbol. But LDPC decoding is not based on isolated bit decisions. It works because bits are tied together by parity check equations. So the check node messages begin the process of using the relationship among bits. The main question at this stage is: Now that every bit has an initial belief, how can each parity check node start using the beliefs of its connected bits to help detect which bits may be wrong ? The initial check-to-variable messages contain no information yet, so the implementation starts them at zero before the first round of message passing.
Step 14 : Start iterative message passingNow the real LDPC decoding process begins. Until this point, most of the work was preparation. The receiver received noisy symbols.
Now the decoder has two things.
The question now becomes: Can these two sources of information help each other ? This is the main idea of iterative message passing. At the beginning, each variable node has only its own channel-based belief. It may say:
But each bit is not alone. Each bit is connected to multiple parity check equations. Each parity check equation is also connected to multiple bits. So one bit can affect other bits through check nodes, and other bits can affect this bit in return. This is why LDPC decoding is iterative. The decoder does not try to solve the whole codeword in one shot. Instead, it lets messages flow through the Tanner graph again and again.
So this step is the start of the repeated conversation inside the LDPC decoder. The decoder is now asking: If every bit tells its current belief to the parity checks, and every parity check replies based on its constraint, can the whole graph gradually agree on a valid codeword ? The iterative decoder now enters its main loop. The configured iteration count limits how long this conversation between graph nodes may continue.
Step 15 : Send messages from variable nodes to check nodesNow each variable node starts sending messages to the check nodes connected to it. A variable node represents one coded bit. So the message from a variable node is basically saying: This is what I currently believe about my bit. At the first iteration, this belief mostly comes from the channel LLR. For example,
But after the first iteration, the message is not only from the channel anymore. The variable node also receives feedback from other check nodes. It combines that feedback with the original channel LLR and sends a new message. There is one important rule here. When a variable node sends a message to one check node, it should not simply send back the information that originally came from that same check node. It should send the channel belief plus the messages from the other connected check nodes. This is important because the decoder tries to avoid circular self-confirmation. So the message from a variable node to a check node means something like this: Based on what the channel told me, and based on what other parity checks told me, this is my current belief about this bit. This step is the variable node’s side of the conversation. The variable node does not yet decide the final bit value. It only sends its current soft opinion to each connected parity check. Then each check node will use the messages from all connected variable nodes to check whether the parity rule looks consistent. So the important question at this stage is: What should each bit tell each parity check, based on the channel observation and the feedback received so far ? Variable-to-check messages are updated from the current variable belief while excluding the feedback from the same destination check node.
Step 16 : Update messages at check nodes using parity check constraintsNow the check nodes receive messages from the variable nodes.
For example, assume one check node is connected to four variable nodes. This means those four bits must satisfy one parity equation. In simple binary form, it may look like this: b1 + b2 + b3 + b4 = 0 mod 2 This means the number of 1s should be even. The check node now looks at the incoming messages from the connected variable nodes and asks: Do these bits look consistent with the parity rule ? If most connected bits look reliable, but one bit looks weak or suspicious, the check node can send strong guidance to that weak bit. For example, if three bits are likely to be: 0, 1, 1 Then the fourth bit should likely be: 0 because 0 + 1 + 1 + 0 gives even parity. But if the fourth bit originally looked weakly like 1, the check node may send a message saying: Based on the other bits in this parity equation, you should probably be 0. This is the core role of the check node. It does not use the channel directly. It uses the parity relationship. It looks at all the other connected bits and calculates what each target bit should be in order to satisfy the parity rule. So the message from a check node to a variable node is like this:
There is also an important reliability aspect.
So the check node message includes both direction and confidence. This is how LDPC uses structure to correct errors. The channel may say one thing. But the parity check may say: That bit does not fit well with the other bits. Maybe this weak bit should be changed. So at this stage, the decoder is asking: From the viewpoint of each parity equation, what should each connected bit be, so that the parity rule can be satisfied ? The internal backend uses a normalized Min-Sum check-node update. It derives outgoing confidence from the signs and the smallest incoming magnitudes from the other connected bits.
Step 17 : Send updated messages from check nodes back to variable nodesAfter each check node updates its opinion, it sends messages back to the variable nodes connected to it. This is the return direction of the message passing. In the previous step, variable nodes said: This is what I currently believe about my bit. Now the check nodes reply: From the viewpoint of this parity check equation, this is what your bit should probably be. This is an important difference.
A check node does not say this bit is 0 or 1 just because of the received signal. It says it because of the relationship among all the other bits connected to the same parity equation. For example, assume a check node is connected to four bits.
So the check node sends a message to that remaining variable node, saying something like: According to this parity check, you are likely to be 0. But the strength of this message depends on the confidence of the other bits.
This is very important. The check node is not just sending a hard command. It is sending a soft suggestion with confidence. A variable node may receive several such messages from different check nodes. Some may agree with the original channel LLR. Some may disagree. Some may be strong. Some may be weak. So after this step, each variable node has more information than before. It still has its original channel opinion. But now it also has opinions from parity checks. The main question at this stage is: What does each parity check equation suggest to each bit, based on all the other bits connected to that same check ? The updated `c2v` array is the collection of check-node replies that will be sent back toward the connected variable nodes in the next belief update.
Step 18 : Update variable node beliefs using channel LLR and incoming check node messagesNow each variable node receives messages from several check nodes. A variable node represents one coded bit. So now this bit has two kinds of information.
Now the variable node combines them. This is where the belief about the bit is updated. For example, the channel may say: This bit is probably 1, but I am not very sure. Then several check nodes may say: From our parity check equations, this bit should probably be 0. If those check node messages are strong enough, the variable node may change its belief from 1 to 0. But if the channel LLR is very strong, and the check node messages are weak, the variable node may keep its original belief. So the variable node does not blindly follow the channel. It also does not blindly follow one parity check. It combines all available opinions. This is the key idea of belief update. Each bit gradually refines its own opinion by listening to the channel and to the surrounding parity checks.
This is why LDPC decoding is powerful.
So at this stage, the decoder is asking: After listening to the channel and all related parity checks, what is the best current belief for each bit ? Each variable node combines its original channel LLR with all incoming check-node messages to form the current total belief.
Step 19 : Make tentative hard decisions for all bitsUntil this point, the decoder has been working with soft values. Each variable node does not simply say 0 or 1. It keeps a belief value. This belief tells two things.
But at some point, the decoder has to ask a very practical question. If I must decide now, what bit value should I choose ? This is the tentative hard decision. For every variable node, the decoder looks at the updated belief value.
For example, with the common LLR convention: Positive LLR becomes hard bit 0. Negative LLR becomes hard bit 1. So the soft belief is converted into a temporary 0 or 1 value. This is called tentative because the decoder is not saying: This is definitely the final answer. It is saying: Based on the current beliefs, this is the current best guess. This distinction is important. The decoder may still be wrong.
Once all bits are tentatively decided, the decoder gets a candidate codeword c. Then the next question becomes very clear. Does this candidate codeword satisfy the LDPC parity rule ? In other words: Does H c = 0 ? So this step is like taking a snapshot of the current soft beliefs and turning them into a binary candidate codeword. The decoder is not finished yet. It is only preparing a candidate answer so that the parity check test can be performed. The current soft beliefs are converted into a temporary binary codeword candidate. Here, a negative conventional BP LLR becomes hard bit 1.
Step 20 : Check whether the tentative codeword satisfies H c = 0Now the decoder has a tentative hard decision for every coded bit. So it has a candidate codeword c. But this candidate codeword is not automatically accepted. The decoder has to check whether it satisfies the LDPC rule. That rule is: H c = 0 Here, H is the parity check matrix. c is the tentative codeword. If c is a valid LDPC codeword, all parity check equations should be satisfied. This means the result of H c should become all zeros. The zero here does not mean the decoded data is all zero. It means there is no parity check violation. Each row of H represents one parity check equation. So when the decoder calculates H c, it is checking all parity check equations one by one.
In binary LDPC, this calculation is done in modulo 2. So the decoder is basically checking whether the number of 1s involved in each parity equation is even. If all rows pass, the tentative codeword is structurally valid. Then the decoder can stop the LDPC iteration. But if even one parity check fails, the current candidate codeword is still not valid. This does not mean the whole decoding process failed yet. It only means the current beliefs are not good enough. Then the decoder goes back to message passing and tries another iteration. This step is important because it gives the decoder a concrete test. Until now, the decoder was updating beliefs. But now it asks a yes-or-no question: Do the current hard decisions satisfy all parity check rules defined by H ?
The candidate codeword is tested against all parity checks through the syndrome function. This is the implementation form of asking whether H c = 0.
Step 21 : If all parity checks pass, stop decodingIf all parity checks pass, the LDPC decoder can stop the iterative decoding process. This means the tentative codeword satisfies: H c = 0 At this moment, the decoder has found a codeword that matches the parity check structure defined by H. This is an important milestone. Until now, the decoder was not fully sure about the received bits. It only had soft beliefs.
But after the hard decision, if every parity check equation is satisfied, the decoder gets strong evidence that the current candidate codeword is a valid LDPC codeword. So it does not need to continue the message passing loop. This is called early stopping. Without this check, the decoder may keep running until the maximum number of iterations is reached, even though it already found a valid codeword earlier. That would waste processing time and power. So the parity check result gives the decoder a practical stopping condition. But one subtle point is important. Passing H c = 0 means the codeword is valid from the LDPC parity check point of view. It does not always guarantee that the decoded transport block is the originally transmitted one. In most normal cases, if the channel condition is good and the code is well designed, passing the parity check is a very strong sign of successful decoding. But in practical NR receiver processing, the final confirmation usually comes later from CRC check. So at this step, the decoder says: The current codeword satisfies all LDPC parity rules. There is no need for more LDPC iterations. Then it moves to the next stage, where the decoded bits are extracted and checked further. When all parity checks pass, the loop stops early instead of wasting the remaining iteration budget.
Step 22 : If parity checks fail, continue to the next iteration (go to step 15)If one or more parity checks fail, the decoder cannot accept the current tentative codeword. This means the current hard decision does not satisfy: H c = 0 Some parity equations are still broken. But this does not mean decoding has completely failed. It only means the current beliefs are not good enough yet. So the decoder goes back to the message passing loop. More specifically, it goes back to the step where variable nodes send updated messages to check nodes.
All of those are already fixed. Only the messages on the Tanner graph are updated again. This is the key idea of iterative decoding.
When a parity check fails, it is like the graph saying: The current bit opinions do not agree with the parity rules yet. Then the check nodes and variable nodes exchange messages one more time.
Then the decoder makes another tentative hard decision and checks H c = 0 again. So the loop is:
The important question at this stage is: Can another round of message passing make the bit beliefs more consistent with all parity check equations ? If the parity checks do not pass, the decoder does not restart the entire receiver chain. It simply updates the variable-to-check messages and runs another iteration.
Step 23 : Repeat message passing until success or maximum iteration count is reachedIf the parity check still fails, the decoder keeps repeating the message passing process. This repetition is the heart of LDPC decoding. The decoder does not usually solve the correct codeword in one step. Instead, it improves the bit beliefs little by little. In every iteration, variable nodes send their current beliefs to check nodes. Check nodes examine those beliefs using parity check rules. Then check nodes send updated suggestions back to variable nodes. Variable nodes combine those suggestions with the original channel LLR and update their beliefs again. After each iteration, the decoder makes a tentative hard decision and checks: H c = 0
Do I still have iteration budget left ? The decoder cannot repeat forever. So practical LDPC decoders use a maximum iteration count. For example, the decoder may allow 10, 20, 30, or some configured number of iterations. The exact value depends on implementation, performance target, latency limit, and power consumption. This creates a tradeoff. More iterations may improve the chance of successful decoding. But more iterations also mean more processing time, more power consumption, and more decoding latency. So the decoder keeps trying only up to a limit. If decoding succeeds before the maximum count, it stops early. If the maximum count is reached and parity checks still fail, the LDPC decoding attempt is considered unsuccessful. This step shows an important nature of LDPC decoding.
The channel says: This is what I think each bit is. The parity check structure says: These bits must satisfy these relationships. The decoder repeats this conversation until the whole codeword becomes consistent, or until it gives up after too many attempts. The fixed iteration loop expresses the practical stopping rule: keep trying until either parity succeeds or the maximum iteration count is reached.
Step 24 : If decoding succeeds, extract the systematic information bitsIf LDPC decoding succeeds, the decoder now has a valid decoded codeword. This codeword satisfies the LDPC parity check rule. H c = 0 But the whole codeword is not the original transport block. It contains different kinds of bits.
So after decoding succeeds, the receiver has to extract the part that actually carries the original information. In NR LDPC, the code is systematic. This means the original information bits are included directly in the codeword structure, instead of being completely transformed into something unrecognizable. This is helpful. Because once the decoder recovers the full codeword, it can take the systematic part and use it as the decoded information block. The parity bits were needed for error correction. They helped the decoder check and repair the received data. But after decoding is done, those parity bits are not the final payload that higher layers want. So the receiver now separates the useful information bits from the full decoded codeword. Conceptually, this step is like saying: : The parity bits helped me recover the message. Now I only need to take out the original message part. This is another important distinction. LDPC decoding does not directly output the final transport block in one simple step. It first recovers a valid codeword. Then the receiver extracts the systematic information bits from that codeword. The main question at this stage is: Now that I have a valid LDPC codeword, which part of it is the original information that should be passed to the next processing step ? After successful decoding, the decoder returns the systematic information portion of the recovered codeword rather than the whole mother codeword.
Step 25 : Remove filler bits from the decoded information block if usedIn NR LDPC, the original information block does not always fit perfectly into the LDPC code block structure. The LDPC encoder expects a certain block size. But the actual transport block or code block may be smaller than that size. So the transmitter may insert filler bits. These filler bits are not real user data. They are only added to make the block fit the size required by the LDPC encoding structure. Conceptually, the transmitter is saying: My real information bits are not enough to fill this LDPC input block. So I will add dummy bits in the unused positions. These filler bits are usually treated as known bits, often zero, during encoding. But they should not appear in the final decoded transport block. They are only temporary helper bits used to fit the LDPC code structure. At the receiver side, after LDPC decoding, these filler positions have to be removed. Otherwise, the recovered bit sequence would contain extra bits that were never part of the original data. This step is easy to underestimate. But it is important because the decoder output is still shaped by the LDPC code block format. The higher layer does not want the LDPC-shaped block. It wants the original information block. So the receiver asks: Which bits were real information bits, and which bits were only filler bits added for LDPC encoding ? Then it removes the filler bits and keeps only the meaningful data bits. This is another reminder that LDPC decoding is not only about correcting errors. It is also about restoring the exact bit structure that existed before LDPC encoding and rate matching. The code-block decoder returns only the real information part requested by `K_prime`, so filler bits beyond the useful payload are removed before later processing.
Step 26 : Perform CRC checkAfter the LDPC decoder extracts the information bits and removes unnecessary parts such as filler bits, the receiver still needs one final confirmation. This is the CRC check. CRC means Cyclic Redundancy Check. At first, this may look similar to parity check, but the role is different. The LDPC parity check is used inside the decoding process. It checks whether the decoded codeword satisfies: H c = 0. But CRC is used to check whether the recovered information block is correct. This is important because passing the LDPC parity check does not always guarantee that the final transport block is correct. In most cases, it is a very strong sign. But theoretically, the decoder may still converge to a wrong but valid codeword. Or some error may remain after decoding. So the CRC gives another layer of protection. At the transmitter side, CRC bits were calculated from the original data and attached before channel coding. At the receiver side, after decoding, the receiver calculates the CRC again from the recovered data and compares it with the received CRC bits.
So this step asks a very practical question: Even if the LDPC structure looks satisfied, is the recovered transport block really the one that was transmitted ? This is why CRC is the final judge.
The recovered transport block is then checked by CRC. The implementation chooses CRC24A or CRC16 according to the transport-block CRC length.
Step 27 : If CRC passes, deliver the decoded transport blockIf the CRC check passes, the receiver finally accepts the decoded data. This means the receiver has strong confidence that the transport block was recovered correctly. Until this point, many things have happened.
Now, if the CRC passes, the receiver can say: This decoded transport block is valid. At this point, the decoded transport block can be delivered to the next processing stage.
This is the point where the data leaves the channel decoding world and moves back into the normal protocol stack. So the LDPC decoder’s job is almost finished. It does not need to keep worrying about parity checks, Tanner graphs, variable nodes, or check nodes. Those were internal tools used to recover the data. Once the CRC passes, the receiver treats the transport block as successfully decoded. The important question at this stage is: Now that both LDPC decoding and CRC verification succeeded, can this recovered block be trusted and passed to the next layer ? The answer is yes. So the decoded transport block is delivered upward. When CRC passes, the decoded payload bits and hexadecimal payload are stored as the valid transport-block result for the rest of the receiver.
Step 28 : If CRC fails, declare decoding failure or request retransmission through HARQIf the CRC check fails, the receiver cannot accept the decoded transport block. This means something is still wrong. The LDPC decoder may have finished its iterations. It may even have produced a candidate output. But the CRC says that the recovered information block does not match the original transmitted block. So the receiver has to treat this decoding attempt as failed. This is an important point. LDPC decoding may try very hard to repair the received bits, but it is not the final judge. The final confirmation comes from CRC. If CRC fails, the receiver should not pass the decoded transport block to the higher layer as valid data. Then the next question becomes: What should the receiver do with this failed block ? In NR, the usual answer is HARQ. HARQ means Hybrid Automatic Repeat Request. If the receiver cannot decode the transport block successfully, it can request retransmission. But it does not simply throw away everything it already received. This is where HARQ becomes powerful. The receiver may keep the soft information from the failed decoding attempt. When the retransmission arrives, the receiver combines the new received soft information with the previous soft information. Then LDPC decoding is tried again with stronger evidence. So a failed CRC does not always mean starting from zero. It often means:
This is why HARQ and LDPC work together.
So at this final step, the receiver asks: Did the decoded block pass the final integrity check ?
When CRC does not pass, the scanner can try HARQ soft combining with other eligible transmissions rather than treating every failed attempt as useless.
Why LDPC is Compute-Intensive ?LDPC (Low-Density Parity-Check) codes are compute-intensive primarily due to the iterative nature of their decoding process, the complexity of the operations involved, and the scale of the matrices used in modern systems like 3GPP’s 5G NR. While LDPC codes offer excellent error correction performance, their computational demands stem from several factors. Let’s break this down in detail, focusing on the encoding and decoding processes, and how they apply in the context of 3GPP. Iterative Decoding ProcessThe primary reason LDPC is compute-intensive is its decoding algorithm, which typically uses an iterative message-passing approach, such as the Belief Propagation (BP) algorithm or its variants (e.g., Min-Sum algorithm). Here’s why this is computationally demanding:
Large Parity-Check MatrixThe size and structure of the parity-check matrix H contribute to the computational intensity:
Floating-Point or Fixed-Point Arithmetic
Encoding Complexity (Though Less Intensive Than Decoding)While encoding is generally less compute-intensive than decoding in LDPC, it still contributes to the overall computational load:
High Throughput Requirements in 5G NR
Memory and Data Movement
Mitigations in 3GPPWhile LDPC is compute-intensive, 3GPP’s 5G NR design includes several optimizations to manage this complexity:
Comparison to Other Codes
Reference[1] 3GPP TSG RAN WG1 #86 - R1-166414 Discussion on LDPC codes for NR [2] 3GPP TSG RAN WG1 #86 R1-166769 Discussion on Length-Compatible Quasi-Cyclic LDPC Codes [3] 3GPP TSG RAN WG1 #86 R1-166770 Discussion on Rate-Compatible Quasi-Cyclic LDPC Codes [4] 3GPP TSG RAN WG1 #86 R1-166929 LDPC Code Design for NR [6] 3GPP TSG RAN WG1 #86 R1-167889 Design of Flexible LDPC Codes
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||