|
|
||
|
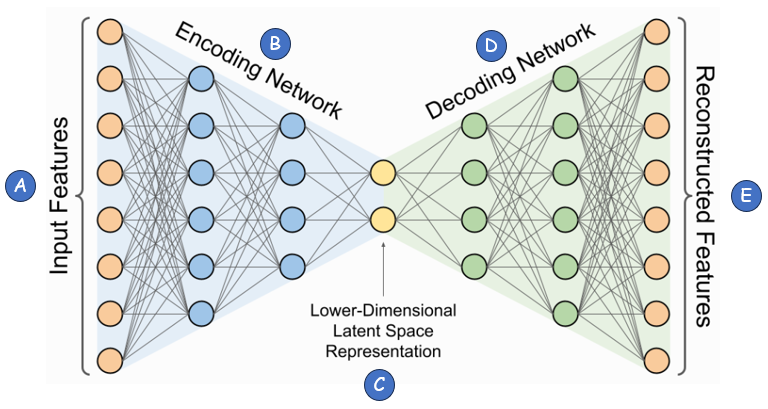
An autoencoder is a cool machine learning model that learns to copy its input data in a smart way. Unlike some models that need labeled examples, this one works on its own, without any help, which makes it great for tasks like shrinking data, removing noise, or finding key features. It has two main parts: an encoder that reduces the data into a smaller version, and a decoder that rebuilds it to match the original. The goal is to make the output as close as possible to the input, and while doing this, it finds hidden patterns by itself. This makes autoencoders very useful for things like improving blurry photos or detecting unusual things in data, all while keeping things simple and interesting in the world of AI! Archtiecture OverviewThe architecture of an autoencoder is a neatly designed structure that powers its ability to learn and recreate data. It starts with an input layer that takes in the raw data, like a picture or a set of numbers. This data then flows into the encoder, a series of layers that gradually shrink it down into a smaller, compact version called the latent space. Think of this as the model’s way of summarizing the most important details. From there, the decoder takes over, using another set of layers to expand that compact version back into something as close as possible to the original input. The whole setup looks a bit like an hourglass—wide at the ends and narrow in the middle—and it’s trained to make the output match the input by adjusting the connections between layers. This clever design is what makes autoencoders so good at tasks like data compression or cleaning up messy information! In short, an autoencoder is a type of artificial neural network used for unsupervised learning, primarily for dimensionality reduction, feature extraction, and data reconstruction. It learns a compressed representation (latent space) of input data and then reconstructs it as closely as possible.
Image Source : Introduction to Variational Autoencoders Using Keras Let's break down the architecture into each components and their functions.
An autoencoder might look like a supervised network at first glance because of its structure—data goes in, gets processed, and comes out with a clear goal of matching the input. But it’s classified as an unsupervised network because it doesn’t rely on labeled data to learn. In a supervised model, you’d give it pairs of inputs and specific outputs, like showing it a picture and telling it “this is a cat” to train it. With an autoencoder, there’s no such guidance. Instead, it uses the input data itself as the target. The model learns by trying to recreate the input—like a photo or a set of numbers—without being told what that input means or what to look for. The confusion often comes from the diagram: the encoder squeezes the data, the decoder rebuilds it, and the training process compares the output to the input to improve. This comparison might feel like supervision, but it’s just the model checking its own work against the raw data it started with, not against pre-made labels. Since it figures out patterns and features on its own, without any external hints or categories, it fits squarely in the unsupervised category. It’s like teaching itself to draw a picture by looking at the original, rather than having a teacher say, “Here’s how it should look.” That self-reliant learning is what makes it unsupervised, despite the structured setup! In summary, it can be bulletized as below
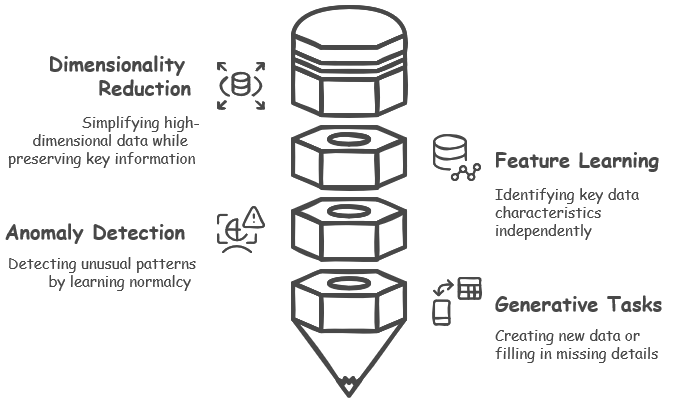
Use CasesAutoencoders are incredibly versatile tools in machine learning, finding their place in a variety of practical applications thanks to their unique ability to learn from data without needing explicit instructions. Some of the common categories of applications are
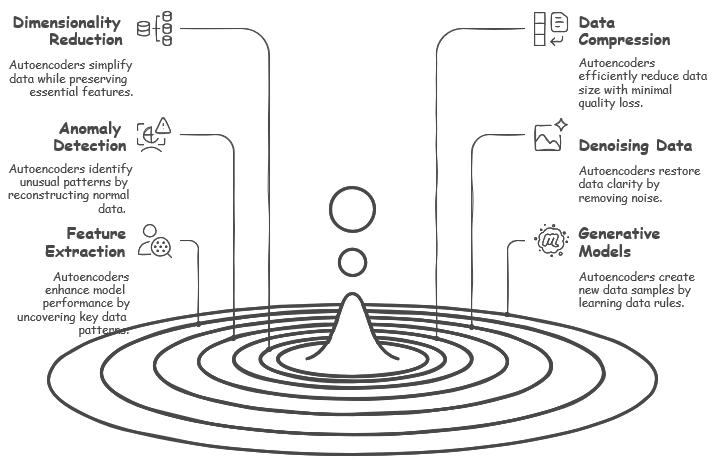
General Use Cases of AutoencodersAutoencoders are a fascinating class of neural networks widely used in various applications due to their ability to learn efficient data representations. They work by compressing input data into a lower-dimensional latent space and then reconstructing it, capturing essential features while discarding noise. This unique architecture enables autoencoders to serve multiple purposes, such as dimensionality reduction to simplify data while preserving its core characteristics, anomaly detection by identifying patterns that deviate from the norm, and feature extraction to enhance model performance by uncovering critical data patterns. Additionally, autoencoders are valuable for data compression with minimal quality loss, denoising by restoring clarity to noisy data, and even powering generative models that create new data samples by learning underlying data rules. Their versatility makes them a powerful tool in fields like machine learning, data analysis, and beyond.
Autoencoders are fantastic at dimensionality reduction, a process where they take high-dimensional data and shrink it down while still holding onto the most important features. This is somewhat similar to PCA, or Principal Component Analysis, which also simplifies data, but autoencoders have an edge because they can pick up on nonlinear structures that PCA might miss. For example, they can lower the resolution of an image—making it smaller and less detailed—while still keeping the key visual elements that make it recognizable, like the shape of a face or the outline of an object. This ability to compress data effectively while preserving what matters makes them a powerful tool in many applications!
Autoencoders are powerful tools for data compression, as they learn to create compact representations of data that make storage and transmission much more efficient. Unlike traditional compression methods like JPEG for images or MP3 for audio, which follow set rules to reduce file size, autoencoders stand out by capturing nonlinear dependencies—complex, wavy patterns in the data that simpler techniques might overlook. For example, in image compression, an autoencoder can take a detailed picture, encode it into a smaller, lower-dimensional version that keeps the critical essence, and then reconstruct it later with surprisingly little loss of quality. This knack for squeezing data down while preserving its core makes autoencoders a smart choice for handling big files in a modern, flexible way!
Autoencoders excel at anomaly detection because they’re trained to recreate normal data accurately, so when something unusual pops up, they struggle to reconstruct it properly. This makes them incredibly useful in areas like fraud detection, cybersecurity, and medical diagnosis, where spotting the odd one out is crucial. For instance, in credit card fraud detection, an autoencoder learns what typical transaction patterns look like—say, regular purchases at familiar stores. If a transaction comes along that’s wildly different, like a sudden expensive buy in a strange location, the model won’t be able to rebuild it well and flags it as potential fraud. This knack for highlighting deviations from the norm turns autoencoders into a trusty tool for keeping systems safe and reliable!
Denoising autoencoders are like skilled restorers, capable of cleaning up noise from various types of data, such as images, audio, and text. They work by learning how to reconstruct the original, clear version of the data even when it’s been muddied up with unwanted distortions. For example, they can take an old, blurry photograph and sharpen it, bringing out details that were lost to time, or they can enhance a fuzzy speech signal, making the words crisp and easier to understand. This ability to sift through the mess and pull out the clean, meaningful parts makes denoising autoencoders a go-to solution for improving the quality of all sorts of data!
Autoencoders are great at feature extraction for supervised learning, where they dig into data to uncover meaningful representations that can boost tasks like classification. They do this by learning the essential patterns and structures within the data on their own, creating a solid foundation that other models can build on. For example, in image recognition, you might pretrain an autoencoder to study a bunch of pictures and figure out what’s important—like edges, shapes, or textures. Then, when you use that knowledge in a supervised model to classify images (say, sorting cats from dogs), it performs better because the autoencoder has already highlighted the key details. This teamwork between unsupervised learning and supervised tasks shows how autoencoders can make complex challenges a lot easier!
Generative models like variational autoencoders, or VAEs, take the creativity of autoencoders to the next level by producing entirely new synthetic data samples from scratch. Unlike regular autoencoders that just recreate what they’re given, VAEs learn the underlying rules of the data and use that to whip up fresh creations, making them perfect for artistic and innovative tasks. For instance, they’re used in art creation to design unique paintings, in image synthesis to craft realistic pictures that never existed before, and even in deepfake generation to produce convincing video alterations. This ability to generate something new and believable showcases how VAEs push the boundaries of what autoencoders can do, blending machine learning with imagination!
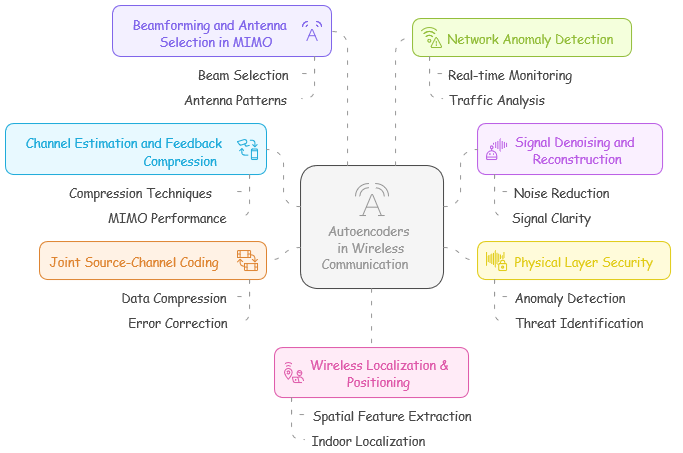
Autoencoders in Wireless CommunicationAutoencoders have emerged as a transformative tool in wireless communication. Their ability to efficiently compress, reconstruct, and analyze data makes them invaluable across a range of applications, from enhancing MIMO performance through beamforming and antenna selection to improving channel estimation and feedback compression. It play roles in network anomaly detection for real-time monitoring and traffic analysis, as well as signal denoising and reconstruction to reduce noise and enhance signal clarity. Additionally, autoencoders contribute to physical layer security by detecting anomalies and identifying threats, while also enabling wireless localization and positioning through spatial feature extraction and indoor localization. This versatility underscores their significance in advancing the efficiency, security, and performance of modern wireless systems.
In the world of 5G and future wireless technologies, getting accurate Channel State Information (CSI) estimation is essential for ensuring smooth and efficient data transmission. Autoencoders step in as a clever solution here, tackling two big challenges at once. They can compress CSI feedback, shrinking the amount of data that needs to be sent back and forth, which cuts down on overhead and keeps the system running light and fast. At the same time, they boost the performance of MIMO systems—short for Multiple-Input Multiple-Output—where multiple antennas work together to send and receive signals more effectively. For example, in massive MIMO setups, which use tons of antennas to handle huge amounts of data, deep learning-based autoencoders refine CSI feedback, making sure the network stays sharp and reliable even under heavy demand. This dual talent for compression and enhancement shows how autoencoders are shaping the future of wireless communication!
Wireless signals often face a rough journey, getting scrambled by interference and noise that can muddy the message. Denoising autoencoders come to the rescue here, acting like a filter to clean up those messy received signals before they’re decoded. They learn to separate the true signal from the unwanted distortions, restoring clarity to the data. For example, in a situation where multipath interference—when signals bounce off objects and arrive at slightly different times—makes a wireless signal messy, a denoising autoencoder can smooth it out, pulling the original signal back into focus. This ability to tidy up and reconstruct signals makes autoencoders a handy tool for ensuring clear, reliable communication in wireless systems!
Wireless networks can be shaky ground, easily targeted by eavesdropping or jamming attacks that threaten their security. Autoencoders offer a clever defense in the physical layer by keeping an eye on transmission patterns and spotting anything that looks off. Since they’re great at learning what normal communication looks like, they can detect anomalies—unusual blips or disruptions—that might signal malicious activity. For instance, in a 5G network, an autoencoder could pick up on a rogue base station pretending to be legit, flagging it as a potential threat before it causes harm. This knack for catching trouble early makes autoencoders a valuable ally in tightening up the security of wireless systems!
In traditional communication systems, source coding—compressing the data—and channel coding—adding protection against errors—are handled as separate steps, each doing its own job. Autoencoders shake things up by combining these two into one smooth process, called joint source-channel coding, which optimizes both at the same time for better error correction. By learning how to compress data and safeguard it against noise in a single go, they make the system more efficient and resilient. For example, in an end-to-end learning setup, an autoencoder can encode a message, send it through a noisy channel, and decode it on the other side, figuring out the best way to pack and protect the data all at once. This streamlined approach shows how autoencoders can rethink communication for stronger, smarter performance!
In MIMO systems, where multiple antennas send and receive signals, beamforming and antenna selection are key to making the most of the available spectrum. Autoencoders step in to optimize this process, fine-tuning beam selection to boost spectral efficiency—essentially getting more data through with less waste. They learn how to pick the best antenna patterns and direct signals more effectively, cutting through the complexity of managing multiple beams. For example, in millimeter-wave (mmWave) communications, which use super-high frequencies for fast data rates, an autoencoder can simplify beam management by reducing the heavy computation needed to figure out the best setup. This smart optimization makes autoencoders a game-changer for faster, more efficient wireless networks!
Wireless networks churn out massive amounts of data logs every second, tracking everything from signal strength to user activity. Autoencoders are perfect for sifting through this flood of information, spotting anomalous network behavior in real-time by learning what’s normal and flagging what’s not. Their ability to catch odd patterns fast makes them a powerful tool for keeping networks stable and secure. For instance, in LTE or 5G core networks, an autoencoder could detect a Denial of Service (DoS) attack—where someone floods the system to crash it—by noticing unusual spikes or disruptions that don’t match typical traffic. This quick response to trouble helps autoencoders protect wireless networks from chaos and threats!
Autoencoders enhance wireless localization and positioning by extracting spatial features from received signals, thereby improving accuracy, as demonstrated in applications like indoor localization using Wi-Fi signals
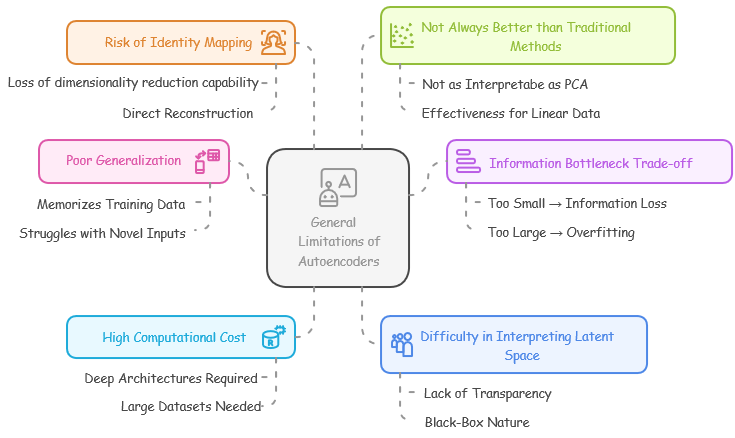
Limitations and Challenges of AutoencodersWhile autoencoders are powerful for feature learning, data compression, and anomaly detection, they come with several limitations and challenges. These issues arise from their training process, generalization ability, and practical deployment. General Limitations of Autoencoders
Autoencoders frequently exhibit poor generalization, tending to memorize the training data rather than acquiring broadly applicable patterns. Consequently, they encounter difficulties when attempting to reconstruct inputs that are either entirely novel or only slightly deviate from the training distribution. For instance, a denoising autoencoder trained to eliminate particular noise patterns may prove ineffective when presented with previously unencountered noise types.
The information bottleneck trade-off in autoencoders presents a challenge in determining the optimal size of the latent space, which is intended for compressed representations. If the latent space is excessively small, crucial information may be lost. Conversely, an overly large latent space can lead to overfitting, causing the model to store superfluous details. For example, when applying autoencoders to image compression, a restricted latent space might result in the loss of subtle, fine-grained image details
Autoencoders often demand substantial computational resources due to their need for deep architectures to handle complex tasks. Their training is particularly expensive, necessitating large datasets and powerful GPU resources, especially when processing high-dimensional inputs such as images. For instance, training a convolutional autoencoder on extensive datasets like ImageNet requires a significant allocation of computational resources.
Autoencoders present a challenge in interpreting their latent space, as they learn black-box representations, unlike methods such as PCA which provide explicit principal components. This lack of transparency makes it difficult to understand precisely how data is encoded within the latent space. For example, in medical applications, it becomes problematic to explain the model's compression of features found within patient records.
A significant risk with autoencoders is that of identity mapping, a form of overfitting. When the model possesses excessive capacity, it may simply replicate the input to the output, bypassing the intended learning of compressed representations. This behavior undermines the fundamental purpose of dimensionality reduction. For instance, if an autoencoder is configured with an excessively large latent space, it may fail to achieve meaningful data compression, instead opting for a direct reconstruction of the input.
Autoencoders, while powerful, do not consistently outperform traditional methods such as Principal Component Analysis (PCA) for feature reduction. PCA offers greater interpretability, requires less parameter tuning, and is particularly effective for linearly structured data. 1 For example, in the context of financial datasets, PCA may achieve superior dimensionality reduction compared to autoencoders, and without the complexities associated with deep learning models.
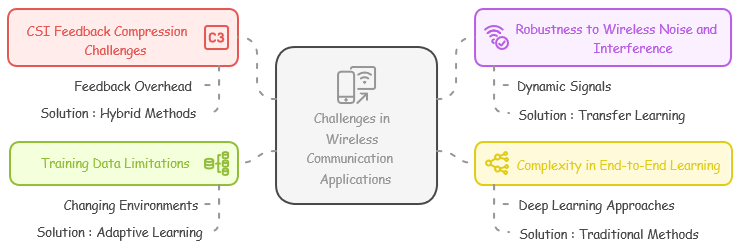
Challenges in Wireless Communication Applications
While autoencoders offer a means to reduce feedback overhead in Channel State Information (CSI) compression, a key challenge lies in ensuring the reconstructed CSI maintains sufficient accuracy. To address this, hybrid methods are being explored. Hybrid methods in CSI feedback compression combine the reliability of traditional channel estimation with the efficiency of deep learning autoencoders. This approach aims to improve accuracy by using traditional techniques to enhance or correct the autoencoder's output, or by using them to prepare or select features for the autoencoder. Essentially, it's about intelligently blending established methods with deep learning to optimize CSI reconstruction.
Wireless signals are inherently dynamic, affected by factors like multipath fading, which poses a robustness challenge for autoencoders. Models trained under specific conditions may falter in real-world environments. To mitigate this, techniques like transfer learning or adaptive training are employed, enabling the autoencoder to adapt to evolving network conditions.
Although deep learning, particularly autoencoders, has been explored for end-to-end modulation and coding in wireless communication, these approaches face practical limitations. Consequently, traditional methods such as LDPC and Turbo codes continue to be the prevailing standards in cellular systems.
Training autoencoders for wireless applications is hampered by the difficulty of collecting representative datasets due to the constantly changing nature of wireless environments. To address this, real-time adaptive learning and reinforcement learning techniques are being explored.
Reference :
YouTube :
|
||