|
|
||
|
Recurrent Neural Networks (RNNs) are a class of neural networks designed for processing sequential data by maintaining a form of memory across time steps. Unlike traditional feedforward networks that treat each input independently, RNNs are structured to capture temporal dependencies by passing information from one step of the sequence to the next through hidden states. This makes them particularly effective for tasks where context and order are essential, such as language modeling, speech recognition, and time-series forecasting. The recurrent connections within the network allow it to learn patterns that span multiple time steps, enabling it to make predictions based on both current inputs and previously seen data. It is designed to process sequential data by maintaining a hidden state that captures information from previous inputs, making them particularly suited for tasks like natural language processing, speech recognition, and time-series analysis. Unlike traditional feedforward neural networks, RNNs incorporate loops that allow them to reuse computations across sequences, effectively modeling temporal dependencies and context. Why RNN ?Recurrent Neural Networks (RNNs) are used because they are uniquely suited to handle sequential data where the order and context of elements matter. Traditional neural networks lack the capability to retain information from previous inputs, making them ineffective for tasks like language translation, speech recognition, or time-series prediction. RNNs address this limitation by incorporating loops within the network that allow information to persist across time steps, enabling the model to learn from the sequence and dependencies within the data. This ability to model temporal dynamics and maintain context over time is what makes RNNs a powerful tool for problems where understanding the sequence as a whole is crucial.
What were there before RNN ?RNN is desgined mainly to forecast (predict) something mostly along the axis of time (i.e, temporal axis). What kind of techniques were used for this before RNN ? We can think of this in the context of conventional statistical method and in the context of neural network. In the context of convenstional statistical method, time-series forecasting and sequence modeling were primarily handled using traditional statistical methods and linear models. Techniques such as Autoregressive (AR), Moving Average (MA), Autoregressive Integrated Moving Average (ARIMA), and Exponential Smoothing were commonly used to predict future values based on past observations. These models were grounded in statistical theory and often relied on assumptions of linearity and stationarity, which limited their ability to capture complex, non-linear patterns in data. While effective for certain types of structured and well-behaved data, these approaches struggled with tasks requiring the modeling of long-term dependencies or contextual relationships, which later made RNNs a more powerful alternative in many forecasting applications. Speaking of neural networ, before the advent of RNNs, most neural network-based models for prediction and classification relied on feedforward neural networks. These networks process inputs in a single pass—from input to output—without any mechanism to retain or refer back to previous inputs. Common architectures included Multilayer Perceptrons (MLPs), which were widely used for tasks like classification, regression, and simple pattern recognition. While MLPs could approximate complex functions, they lacked the ability to model sequences or temporal dependencies because they treated each input independently.To handle sequential data, early attempts with MLPs often involved manually engineering features—such as including lagged variables or using fixed-size sliding windows over time-series data. However, these approaches were limited in flexibility and scalability, especially when the temporal relationships were long or variable in length. The introduction of RNNs marked a significant breakthrough by embedding memory and recurrence directly into the architecture, enabling neural networks to naturally process sequences and learn from them over time, something feedforward networks couldn't do effectively. Conventional Statistical Methods
Neural Network-Based Approaches (Before RNNs)
What RNN Introduced
Challenges/LimitationsDespite their strengths in handling sequential data, Recurrent Neural Networks (RNNs) come with several inherent challenges and limitations that can affect their performance and scalability. One of the most well-known issues is the problem of vanishing and exploding gradients, which arises during backpropagation through time and hampers the network’s ability to learn long-term dependencies. RNNs also tend to be computationally expensive due to their sequential nature, making parallelization difficult and training slower compared to feedforward networks. Additionally, they can struggle with retaining information over long sequences and are sensitive to input length and initial conditions. These limitations have led to the development of more advanced architectures like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), which were specifically designed to address some of the shortcomings of traditional RNNs.
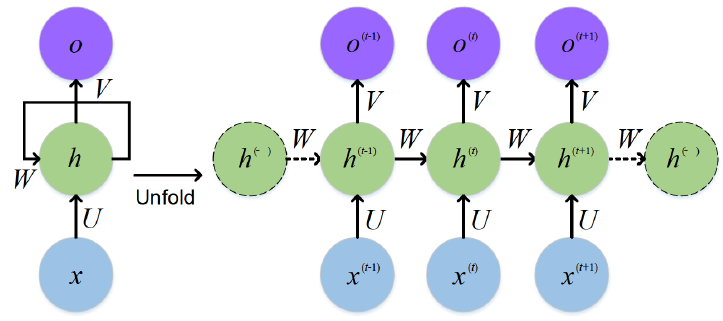
ArchitectureThe architecture of a RNN is designed to process sequences of data by incorporating loops that allow information to persist across time steps. At its core, an RNN consists of an input layer, a hidden layer with recurrent connections, and an output layer. Unlike feedforward networks, where data flows in a single direction, RNNs maintain a hidden state that is updated at each time step based on both the current input and the previous hidden state. This recursive structure enables the network to retain memory of previous inputs and to use this contextual information when processing the current input. The same set of weights is shared across all time steps, making the model efficient and consistent for sequential data processing. This unique architectural design allows RNNs to model temporal patterns and dependencies, which are essential for tasks like language modeling, speech recognition, and time-series prediction.
The most common representation of RNN architecture is illustrated as below. The left side shows the compact version of a single RNN cell, and the right side shows the network unfolded in time. At each time step t, the RNN receives an input
Source : Audio visual speech recognition with multimodal recurrent neural networks Followings are breakdown of this diagram and short descriptions on each component.
Assuming the RNN is used for a next-word prediction task based on the input sequence:
Predicted next word distribution:
Most likely prediction: "weather"
Predicted next word distribution:
Most likely prediction: "is"
Predicted next word distribution:
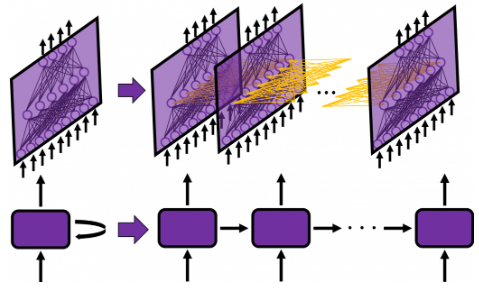
Most likely prediction: "nice" Each output Following is another example of RNN architecture. I think this is a better representation for time-series prediction. In this context, the RNN processes a sequence of numerical inputs arriving over time—such as stock prices, temperatures, or sensor readings—and generates future predictions based on patterns it has learned. The top portion of the image shows the unfolding of network layers across time, while the bottom abstractly represents this behavior through a chain of RNN cells that pass hidden states forward. This enables the model to retain memory of past data and make context-aware predictions for future points in the series.
Source : Simple RNN: the first foothold for understanding LSTM Followings are breakdown of the illustration and description for each component
Assuming the RNN is used for predicting the next day's weather metrics based on past daily measurements. Each input
Output Predicted weather metrics for Day 2:
Most likely prediction: Weather on Day 2 = [23.0°C, 58%, 5.0 m/s] Output Predicted weather metrics for Day 3:
Most likely prediction: Weather on Day 3 = [24.0°C, 56%, 4.3 m/s] Output Predicted weather metrics for Day 4:
Most likely prediction: Weather on Day 4 = [25.0°C, 54%, 4.0 m/s] Reference :
YouTube :
|
||