Sequence-to-sequence (seq2seq) models have revolutionized the field of natural language processing by enabling the transformation of one sequence into another, making them fundamental for tasks such as machine translation, text summarization, and speech recognition. Originally introduced with recurrent neural networks (RNNs), particularly Long Short-Term Memory (LSTM) networks, seq2seq models leverage an encoder-decoder architecture where an input sequence is encoded into a fixed-length representation, which is then used by the decoder to generate an output sequence. The introduction of attention mechanisms significantly improved these models by allowing them to focus on different parts of the input dynamically, leading to more accurate translations and responses. The advent of the Transformer model further enhanced seq2seq performance by replacing recurrence with self-attention, enabling parallel computation and handling long-range dependencies more effectively. Today, seq2seq models remain a core component of many modern AI applications, continuously evolving with innovations in deep learning and optimization techniques.
Why Seq2Seq ?
Seq2seq models are essential because many real-world tasks involve mapping one sequence to another, such as translating a sentence from one language to another, converting speech to text, or summarizing a long document. Traditional machine learning approaches struggled with these problems due to their reliance on fixed-length representations and limited contextual understanding. Seq2seq models, with their encoder-decoder architecture, provide a more flexible and effective solution by encoding the input sequence into a meaningful representation and generating an output sequence dynamically. The introduction of attention mechanisms further improved their capability by allowing the model to focus on different parts of the input at each step of decoding, making them particularly powerful for handling long and complex sequences. Additionally, with advancements like the Transformer architecture, seq2seq models have become even more efficient, enabling faster training and better performance on large-scale tasks. Their adaptability, scalability, and ability to model dependencies across sequences make them indispensable in modern AI applications.
Handles Variable-Length Sequences : Seq2seq models can process input and output sequences of different lengths, making them ideal for tasks like machine translation, summarization, and speech recognition.Encoder-Decoder Architecture : The structured approach of encoding an input sequence into a fixed-length vector and decoding it into an output sequence allows efficient transformation of data across different domains.Context Preservation : Unlike traditional models that struggle with long-range dependencies, seq2seq models retain context using mechanisms like LSTMs, GRUs, and attention.Improved Performance with Attention : Attention mechanisms allow the decoder to selectively focus on relevant parts of the input sequence at each step, improving translation quality and overall accuracy.Adaptability to Various Tasks : Seq2seq models are used in a wide range of applications, including machine translation, chatbots, question-answering systems, and speech-to-text conversion.Better Generalization : By learning meaningful representations of sequences, seq2seq models can generalize well to unseen data, improving robustness and performance across various domains.
What were there before Seq2Seq ?
Seq2Seq models are often compared to traditional sequence-based models that were widely used before deep learning became dominant. Each of these traditional models had its strengths but also faced significant challenges that limited their effectiveness in handling complex sequential tasks.
Statistical Machine Translation (SMT) models , such as IBM Models and phrase-based machine translation (PBMT), relied on probabilistic methods and manually engineered linguistic rules. While they provided structured translations, they struggled with fluency and contextual coherence, often producing unnatural or disjointed output due to their inability to capture long-range dependencies between words.Hidden Markov Models (HMMs ) were popular for sequential tasks like speech recognition and part-of-speech tagging. However, they relied on the Markov assumption, where each state depended only on the previous state, making them insufficient for capturing long-term dependencies. This limitation reduced their effectiveness in modeling complex language structures or predicting sequences with varying contextual influences.Conditional Random Fields (CRFs) improved upon HMMs by allowing for more flexible dependencies between sequential labels, making them useful for tasks like named entity recognition (NER) and sequence labeling. Despite this advantage, CRFs lacked the ability to generate sequences dynamically, restricting their use in generative tasks like translation or text generation.n-gram Language Models estimated the probability of word sequences based on fixed-length word histories, such as trigrams or 5-grams. While they worked well for applications like speech recognition and machine translation, they struggled with data sparsity, requiring extensive smoothing techniques to generalize effectively. Their reliance on short context windows made them ineffective for handling long-range dependencies.Rule-Based Systems depended on manually crafted linguistic rules to process sequences. Although they were useful in specific domains, they were labor-intensive, difficult to scale, and incapable of adapting to unseen or diverse input. Their rigid structure made them inadequate for handling the complexities of natural language.RNNs and LSTMs , which were key components of early Seq2Seq models, also faced challenges when used in isolation. Basic Recurrent Neural Networks (RNNs) processed sequences step by step, maintaining a hidden state to carry information from previous steps. However, they suffered from the vanishing gradient problem, which made it difficult to retain information over long sequences. This limitation hindered their ability to model long-range dependencies effectively.LSTMs (Long Short-Term Memory Networks) were introduced to address the vanishing gradient issue by incorporating gating mechanisms (input, forget, and output gates) that selectively controlled information flow. While they significantly improved sequence modeling by retaining long-term dependencies, they still required sequential processing, which limited their efficiency, especially for long sequences. Moreover, LSTMs became computationally expensive as sequence lengths grew.
Comparing to non-deep learning model (e.g, SMT, HMM etc) Seq2Seq models, with their deep learning-based encoder-decoder framework, overcame these challenges by learning patterns directly from data rather than relying on fixed rules or probabilistic approximations. They effectively captured long-range dependencies and provided more natural and fluent output. The introduction of attention mechanisms further improved their performance by allowing the decoder to focus on relevant parts of the input dynamically. Later advancements, such as Transformers, eliminated recurrence altogether, making Seq2Seq models more scalable, parallelizable, and efficient for large-scale tasks.
Comparing to RNN/LSTM, Seq2Seq models built on these architectures(i.e, RNN/LSTM) by introducing an encoder-decoder framework, allowing input sequences to be compressed into a meaningful context vector before generating the output sequence. However, early Seq2Seq models still relied on a fixed-length context vector, which could cause information loss for long sequences. This challenge was later addressed with attention mechanisms, which enabled the decoder to selectively focus on different parts of the input sequence at each timestep, improving performance on tasks like machine translation and text generation.
Challenges/Limitations
Seq2Seq models have been highly successful in various sequence-to-sequence tasks, but they also come with several challenges and limitations. One of the primary issues is their difficulty in handling long sequences, as early implementations relied on a fixed-length context vector, which often led to information loss, especially for longer inputs. While attention mechanisms helped mitigate this, computational inefficiencies remain a concern, particularly for large-scale tasks. Training Seq2Seq models is also resource-intensive, requiring substantial data and computational power, making them difficult to deploy in real-time applications. Additionally, they are prone to exposure bias, where the model generates sequences based on its own predictions rather than real inputs, leading to compounding errors during inference. Another limitation is their inability to capture structured knowledge effectively, as they generate outputs in a token-by-token manner without an inherent understanding of linguistic or world knowledge. Despite advancements such as Transformers, Seq2Seq models still face challenges with robustness, generalization, and handling out-of-distribution inputs.
Difficulty in Handling Long Sequences : Early Seq2Seq models compressed entire input sequences into a single fixed-length vector, causing information loss. Example: In machine translation, a long sentence may lose key details when encoded into a single vector, leading to poor translations.Computational Inefficiency : Seq2Seq models, especially those with attention mechanisms, require significant computational resources, making them slow and expensive to train. Example: Training a high-quality machine translation model on large datasets requires multiple GPUs and high memory consumption.Exposure Bias : During training, Seq2Seq models receive ground-truth inputs, but during inference, they generate predictions based on previously generated tokens, leading to cascading errors. Example: A chatbot trained on clean data may generate increasingly incoherent responses in real-world conversations when small mistakes accumulate.Limited Generalization to Out-of-Distribution Data : Seq2Seq models struggle when encountering new data that differs from the training set, making them unreliable in dynamic environments. Example: A summarization model trained on news articles may perform poorly on scientific papers with unfamiliar vocabulary and structure.Token-by-Token Generation Issues : Seq2Seq models generate outputs sequentially, lacking a global understanding of the full sentence before generation is complete. Example: In dialogue generation, this can lead to inconsistencies, where the model contradicts itself in later responses.Lack of Explicit Reasoning and Knowledge Representation : Seq2Seq models generate text based purely on statistical patterns without structured knowledge integration. Example: In question-answering tasks, a Seq2Seq model may provide plausible but factually incorrect answers because it lacks logical reasoning capabilities.Parallel Processing Limitations in Seq2Seq Models : One of the major limitations of traditional Seq2Seq models, especially those based on Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, is their lack of parallel processing capability. Since these models generate sequences step by step, each token's prediction depends on the previous token, making it impossible to process all tokens simultaneously. This sequential nature leads to slow training and inference, especially for long sequences. While attention mechanisms improved efficiency by allowing models to focus on different parts of the input at once, true parallelization was not achieved until the introduction of Transformer models, which replaced recurrence with self-attention. However, even with Transformers, scalability remains a challenge, as self-attention mechanisms require computing pairwise interactions between all input tokens, leading to quadratic time complexity.
Architecture
Seq2Seq models are a type of deep learning architecture designed to handle sequence-based tasks such as machine translation, text summarization, and speech recognition. They consist of two main components: an encoder and a decoder. The encoder processes the input sequence and converts it into a fixed-length representation, which is then passed to the decoder. The decoder takes this encoded representation and generates the corresponding output sequence step by step. This framework allows the model to handle variable-length inputs and outputs, making it useful for many natural language processing tasks
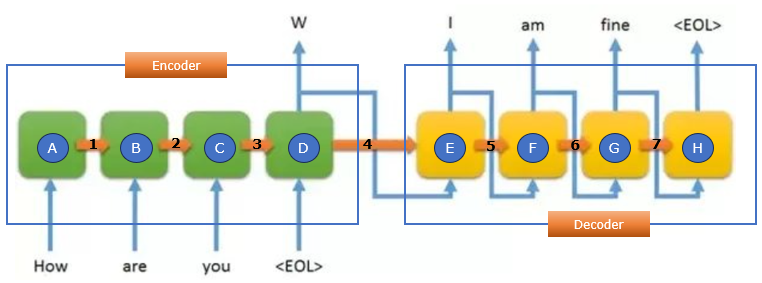
Image Source : Seq2seq Models
Encoder (Green Blocks A-D)
The encoder consists of a series of blocks, each representing a recurrent unit (such as an LSTM or GRU). It processes the input sequence one token at a time and updates a hidden state that carries contextual information forward.
- Block A (How): This is the first token in the input sequence, and its representation is stored in the first hidden state.
- Block B (are): Receives information from Block A and updates the hidden state with additional context.
- Block C (you): Continues processing the sequence, refining the contextual representation.
- Block D (<EOL>): Marks the end of the input sequence and finalizes the encoded representation.
The "W" (the output of Block D in the diagram) represents the context vector, also known as the final hidden state of the encoder. This vector is the encoded representation of the entire input sequence and serves as the only information passed from the encoder to the decoder in traditional Seq2Seq models.
- Compressed Representation of Input ("How are you <EOL>")
- The encoder processes the input sequence word by word, updating its hidden state at each step.
- The last hidden state (W) captures the entire meaning of the input sequence in a fixed-length vector.
- It contains information about word order, meaning, and dependencies learned from the input sequence.
- Bridge Between Encoder and Decoder
- The decoder does not have direct access to the original input words.
- Instead, it receives W (context vector) as the starting point for generating output.
- In early Seq2Seq models (without attention), this vector was the only source of information for the decoder.
- Limitations of a Fixed-Length Context Vector
- If the input sentence is too long, W may not capture all the necessary details, leading to loss of information.
- This limitation is why attention mechanisms were introduced—allowing the decoder to access different parts of the encoded sequence instead of relying on a single vector.
- "W" is passed as the initial hidden state of the decoder (Block E).
- The decoder uses it as a starting point for generating words one by one.
- At each step, the decoder refines this representation by incorporating past predictions.
- Analogy for Understanding "W"
- The encoder reads the full book ("How are you").
- At the end, it writes a short summary (W).
- The decoder uses this summary to generate a response ("I am fine").
- If the summary is too short or lacks details, the decoder may produce incorrect or vague sentences.
- Thus, W is a compressed summary of the input sequence, allowing the decoder to generate meaningful responses even without seeing the original input words directly.
Hidden State Transfer (Orange Arrows 1-7)
Each orange arrow represents the flow of information from one step to the next in the encoder. The hidden state from each token is passed forward to ensure that contextual information is retained.
- Arrow 1: Transfers hidden state from "How" to "are." (i.e, from block A to B)
- Arrow 2: Transfers hidden state from "are" to "you." (i.e, from block B to C)
- Arrow 3: Transfers hidden state from "you" to "<EOL>." (i.e, from block C to D)
- Arrow 4: Passes the final encoded representation to the decoder. (i.e, from block D to E / from Encoder to Decoder)
- Arrow 5: Transfers hidden state from "W" to "I." (i.e, from block E to F)
- Arrow 6: Transfers hidden state from "I" to "am." (i.e, from block F to G)
- Arrow 7: Transfers hidden state from "am" to "fine". (i.e, from block G to H)
- Encoder Arrows (1, 2, 3, 4) – Transfer of Hidden States
- These arrows represent the hidden state transfer within the encoder.
- Each arrow passes the hidden state from one encoder step to the next as the input sequence is processed.
- The purpose is to accumulate context from all previous words, so that by the time the last encoder step (D) is reached, it holds a comprehensive representation of the input sequence.
- At the final step (Arrow 4), the hidden state of the last encoder step is passed to the decoder as the "context vector."
- Example: In a sentence like "How are you?", each word updates the hidden state with its meaning and the meaning of previous words.
- Decoder Arrows (5, 6, 7) – Transfer of Hidden States in Output Generation
- These arrows represent the hidden state transfer within the decoder.
- The decoder operates sequentially, using the previous hidden state and generated token to predict the next word.
- Unlike the encoder, where input is provided externally, the decoder generates tokens one by one, conditioning on its previous outputs.
- Example: If the decoder has generated "I", the hidden state (transferred via Arrow 5) helps predict "am", then "fine".
Decoder (Yellow Blocks E-H)
The decoder generates the output sequence based on the encoded representation received from the encoder.
- Block E (W): The decoder starts with an initial token and generates the first output word.
- Block F (I): Receives the hidden state from the previous step and predicts the next word.
- Block G (am): Uses past outputs to generate the next word in the sequence.
- Block H (fine <EOL>): Produces the final output and marks the end of the sequence.
It seems block A,B,C does not seem to have any output. Why ?
In the encoder part of the Seq2Seq model, blocks A, B, C, and D (which correspond to different words in the input sequence) do not produce direct outputs like the decoder blocks do. Instead, their role is to process and encode the input sequence into a meaningful representation that the decoder can later use.
- They are part of the encoding process
- Each block represents a step in an RNN/LSTM/GRU-based encoder, where the input sequence is transformed into hidden states.
- These blocks pass their hidden state forward to the next block, refining the contextual representation at each step.
- Only the Final Encoder Block (D) Produces a Context Vector
- The last encoder block (D) consolidates the information from all previous words and passes a final hidden state (context vector) to the decoder.
- Blocks A, B, and C contribute to this final context, but they do not generate direct outputs themselves.
- The Encoder Does Not Generate a Sequence
- Unlike the decoder, which produces output words step by step, the encoder's job is to create a compressed representation of the input sequence.
- The decoder then uses this representation to generate the actual output sequence.
- Decoder Generates Words Step by Step
- Unlike the encoder, the decoder produces an output sequence token by token.
- Each decoder block (E, F, G, H) takes the hidden state from the previous step and generates a word as output.
- Outputs are Conditioned on Previous Tokens
- Block E produces "W" as output.
- Block F receives the hidden state from E and generates "I."
- This continues until the sequence is fully generated.
- Encoder Blocks (A, B, C, D): No direct outputs; they encode the input sequence into a final hidden state.
- Decoder Blocks (E, F, G, H): Generate words step by step, using the encoded context.
- The encoder’s role is to compress information, while the decoder’s role is to generate meaningful output from that information.
Without the output, how it can update its weight by back prop ?
Even though the encoder itself does not produce a direct output, it still updates its weights through backpropagation via the decoder’s loss. Let’s break this down step by step.
Seq2Seq models use Backpropagation Through Time (BPTT) across both the encoder and decoder. The key idea is that the encoder does not directly compute a loss, but its parameters still get updated because the decoder’s loss propagates backward through the entire model.
- Forward Pass
- The encoder processes the input sequence (A → B → C → D) and generates a context vector (final hidden state).
- The decoder takes this context vector and starts generating the output sequence step by step.
- Each decoder step produces a token, and the difference between the generated token and the ground truth (correct token) is used to compute the loss.
- Loss Computation at the Decoder
- The decoder generates words one by one (E → F → G → H).
- Each generated word is compared to the expected word (ground truth) using a loss function like cross-entropy loss.
- Example: If the correct sentence is "I am fine" but the decoder generates "I is good", the loss will be high, and the model will adjust weights to improve accuracy.
- Backpropagation from Decoder to Encoder
- The computed loss flows backward through the decoder.
- The decoder’s weights are updated first, using the gradients from the loss function.
- The gradients continue flowing backward through the connections between the decoder and encoder.
- The encoder receives these gradients and updates its weights even though it didn’t have a direct output.
- Weight Updates in the Encoder
- The encoder weights were used to produce the final hidden state (context vector), which influenced the decoder’s predictions.
- Since the loss is computed based on decoder output, any error in predictions is attributed back to the encoder’s contribution.
- The encoder's weights are updated to improve the context vector representation, ensuring that future sequences are better encoded.
Reference :
- Better seq2seq - JakeTae
- Seq2seq Models - CampusX
- 10.7. Sequence-to-Sequence Learning for Machine Translation - Dive Into Deep Learning
- Sequence to Sequence Learning with Neural Networks - arXiv(2014)
-
Flight Demand Forecasting with Transformers - ResearchGate (2021)
YouTube :