There are many different ways for a machine and a human to learn something. It would be difficult to compare machine learning algorithms to human learning processes partly because there can be too many variations and partly because we don’t know exactly what is going on inside of our brain when we learn something. The mystery of human cognition, with its intricate neural networks and countless synaptic connections, remains only partially understood, making direct comparisons challenging. Similarly, machine learning encompasses a wide range of techniques—from supervised learning and neural networks to reinforcement learning—each with its own unique approach and application, further complicating any straightforward analogy. So what I describe in this page is mainly my own subjective opinion and the way I describe is more of analogy rather than the detailed technical or scientific facts. This approach allows for a more accessible exploration of the concept, drawing on familiar imagery and everyday experiences to bridge the gap between the abstract nature of machine processes and the intuitive, often mysterious, ways humans acquire knowledge. By using metaphors like a sponge soaking up water or a computer updating its software, we can begin to grasp the essence of learning in both realms, even if the underlying mechanisms remain distinct and elusive.
- How a Machine Learn ?
- How a Human Learn ?
- Machine vs Human
- Similarify between Machine Learning and Human Learning
- Difference between Machine Learning and Human Learning
How a Machine Learn ?
As I mentioned above, there are many types of algorithm for a machine to learn something, but the model I am trying to explain here is the one based on Machine Learning/Deep Learning which can be illustrated as below.
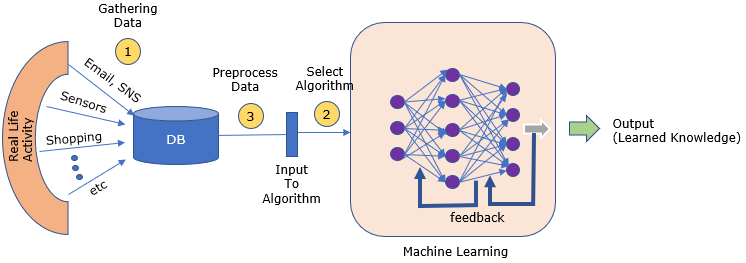
The details of this process is explained in what they do page and the perceptron algorithm would give you more detailed technical details on Machine Learning algorithm part. Just reiterating the process at high level,
- i) another machine (or software) or human prepare huge set of training data (pairs of example data and label for the data)
- ii) the data (training example) is fed to the learning algorithm (neural net).
- iii) the machine learning algorithm evaluate the training data and produce a result (e.g, classification result)
- iv) the machine compares the produced result(estimated result) with the desirect result. // How can it know the desired result ? The desired result was given to the algorithm as a part of training data.
- v) the machine adjust the internal parameters of the machine learning based on the result of the comparision.
- vi) another example data is given to the machine learning algorithm and go to step iii).
Machine learning algorithm repeats the steps from ii)~vi) for thousands, millions of training data.
How a Human Learn ?
Now let's think of how we (human) learn. As mentioned above, we don't know exactly what's happening with each and every neurons in our brain when we learn. It is highly likely that multiple different mechanism is going on in our brain when we are learning. But I get the sense the way I learn something in technology/engineering is very similar to the way a neural network learns.
The way I study/learn about a technical/engineering topics can be illustrated as follows.
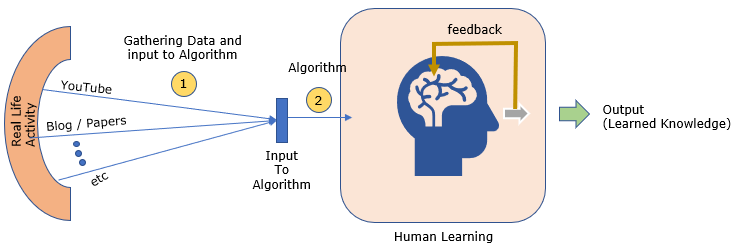
- i) feed training data (e.g, YouTube videos, Blog, Papers etc) into my learning algorithm (my brain)
- ii) my brain produce a summarized information (sometimes I explictely write down the summary or sometimes I imaginarily produce the summary in my brain)
- iii) this process of summrization seems to be fed back to my brain and seems to augment some part of my brain (a kind of circuit for the specific knowledge).
- iv) another training data (e.g, videos, blogs, papers) for the same topic is fed into my brain and go to step ii).
I repeat the steps ii) ~ iv) many times (usually at least around 50 times) for the initial study.
Machine vs Human
In the world of learning, humans and machines follow fundamentally different paths—each marked by its own strengths, limitations, and rhythms. My personal image on the conceptual difference between human learning and machine learning can be illustrated as below. These two illustrations vividly depict the contrast: a human learner, overwhelmed and emotionally entangled, repeatedly tweaking knobs over a lifetime to find the right harmony, versus an AI model, efficiently adjusting weights in minutes through mathematical precision. While human learning is intuitive, emotionally rich, and deeply experiential, it is also slow and often nonlinear. Machine learning, on the other hand, thrives on scale, speed, and repetition, allowing for rapid iteration and optimization. This article dives into the conceptual essence of how learning unfolds in these two realms, using the metaphor of an orchestra and synthesizer to explore what it means to “learn” in a biological brain versus a neural network.
Learning by Huaman
The first illustration captures the deeply personal and often frustrating nature of human learning. Here in this illustrative example, a distressed individual sits before an audio synthesizer, surrounded by musical instruments, each representing a different input or skill. With nine arms awkwardly adjusting knobs, the person reflects a lifelong struggle to fine-tune their internal “parameters”—their habits, reactions, understandings, and behaviors. The speech bubble, “This is not what I want. Let’s change these knobs and try again,” embodies the essence of human learning: a continual process of trial and error, self-reflection, and incremental adjustment. Unlike machines, humans don't come with clear optimization objectives or gradient-based methods. Instead, learning is shaped by emotions, social context, and often ambiguous feedback. Progress can be slow and nonlinear, requiring resilience and adaptability over years, even decades. The caption “This loop goes on lifetime” emphasizes that for humans, learning is not just a technical adjustment—it’s an ongoing, existential endeavor.
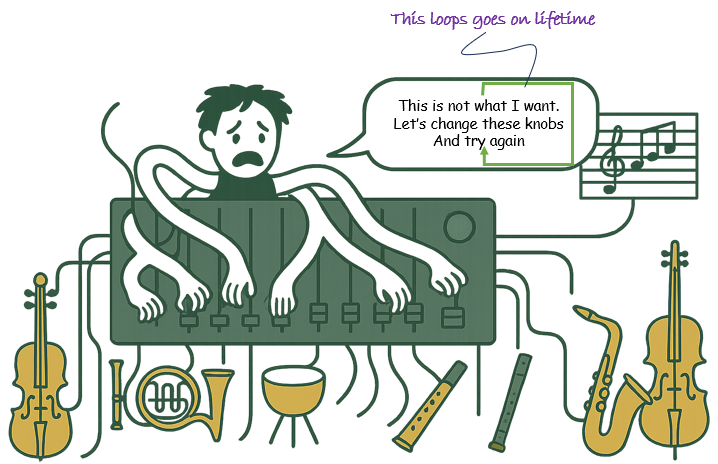
Now let's breakdown this human learning process into multiple aspects and talk briefly about each aspect.
Lifelong, Iterative Process - Human learning is continuous and extends across a lifetime.
- The depicted loop—"This is not what I want. Let’s change these knobs and try again"—symbolizes lifelong experiential learning and adaptation, often described as constructivist learning theory
Emotionally Involved and Motivationally Driven - The character’s facial expression reveals frustration—a nod to how emotions significantly influence cognitive processes such as attention, memory consolidation, and motivation
- Learning often involves emotional highs and lows, which can either enhance or hinder retention and engagement.
Heuristic and Trial-and-Error Based - Unlike machines that optimize using loss functions, humans often rely on heuristic methods—rules of thumb developed from experience.
- This aligns with bounded rationality and dual-process theory, where learning includes both fast, intuitive processes (System 1) and slower, reflective processes (System 2).
Cognitive Load and Limited Working Memory - The multiple arms adjusting knobs metaphorically reflect the cognitive load humans bear during learning.
- According to Cognitive Load Theory, the human brain can only process a limited number of elements simultaneously in working memory.
No Clear Objective Function or Ground Truth - Human learning often occurs in environments with ambiguous feedback or multiple, sometimes conflicting, goals.
- There’s no "ground truth" like in supervised machine learning—this is closer to ill-structured learning environments in educational psychology.
Dependent on Environment and Social Interaction - Although not explicitly shown in the image, real-world human learning is heavily influenced by cultural and social context
- Humans learn through collaboration, modeling, and scaffolding—unlike isolated machine models.
Reflective Self-Regulation - The inner monologue—"This is not what I want"—illustrates metacognition: the ability to evaluate one’s performance and adjust strategies accordingly.
- Self-regulated learning is a hallmark of effective human learning and requires conscious monitoring and adaptation.
Learning by Machine/AI
The illustration shown below offers a conceptual visualization of how machines—particularly neural networks—learn. Unlike the emotionally burdened human learner in the human learning illustration, here we see a faceless, abstract figure composed of interconnected nodes, representing an artificial neural network. This entity adjusts not knobs, but “weights,” symbolized by the letter “W” along the mixer channels. The process is systematic, emotionless, and efficient. The loop—“This is not what I want. Let’s change these weights and try again”—captures the essence of machine learning: a rapid cycle of optimization driven by mathematical loss functions and guided by data feedback. While the human loop unfolds over a lifetime, this machine loop operates at scale, capable of performing millions of iterations in minutes. There is no confusion or second-guessing—just clear objectives and automatic recalibration. This highlights a fundamental difference: machines learn by minimizing error in a structured, quantifiable environment, allowing them to achieve precision and speed that humans cannot match. Yet, this same efficiency comes at the cost of the richness, flexibility, and contextual sensitivity inherent in human learning.
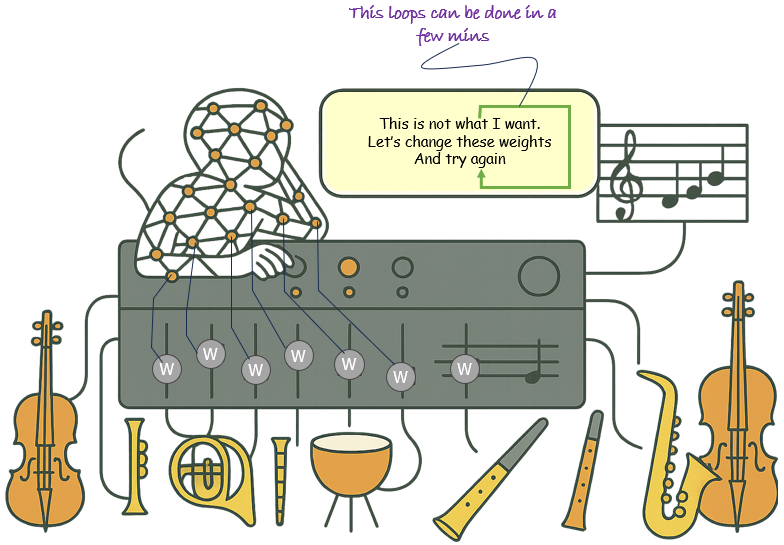
Now let's breakdown this machine (AI) learning process into multiple aspects and talk briefly about each aspect.
Data-Driven and Optimization-Centric - AI learns by minimizing a loss function—a mathematical representation of error between predicted output and actual target.
- The phrase “Let’s change these weights and try again” reflects the gradient descent process used to optimize these weights.
Automated, High-Speed Iteration - Unlike human learning, which unfolds over years, machine learning models iterate over training cycles in minutes or hours.
- This is enabled by scalable compute and batch processing—core to backpropagation and modern deep learning.
Emotionless and Goal-Oriented - Machines lack affective states; learning is not influenced by motivation, frustration, or attention.
- This allows for consistent performance under identical conditions but limits adaptability in ambiguous, real-world settings.
Fixed Objective Functions - Machine learning operates within well-defined problem spaces with known metrics (e.g., accuracy, cross-entropy loss).
- This aligns with supervised learning, where ground truth labels are provided, unlike human environments that often lack clear feedback.
Parametric and High-Dimensional - The knobs replaced by weights (W) symbolize parameters in a neural network—often in the millions or billions.
- These are adjusted using algorithms such as stochastic gradient descent, enabling learning from vast datasets.
No Self-Awareness or Metacognition - Unlike humans who can reflect on their learning strategies (metacognition), AI lacks intrinsic self-monitoring.
- All “reflection” is externally implemented through model evaluation and hyperparameter tuning.
Highly Reproducible and Deterministic (at inference) - Once trained, the model behaves deterministically on identical inputs—ensuring consistency.
- This is a major advantage in industrial applications, contrasting with the variability of human decisions.
Not Contextually Adaptive Without Re-Training - While models excel within their training distribution, they struggle with out-of-distribution generalization unless explicitly designed for it (e.g., transfer learning, continual learning).
- Unlike humans, AI does not generalize well without further data and training cycles.
Similarify between Machine Learning and Human Learning
At first glance, machine learning and human learning might seem like total opposites—one powered by code and data, the other by brains and curiosity—but there’s actually some cool overlap between the two. Both soak up information or experiences to grow smarter, get a boost from feedback to tweak their skills, and can level up with more practice or data, though they can also get a little too fixated on specific stuff. These shared traits give us a fun peek into how learning works, connecting artificial and human intelligence in surprising ways, even if the details are pretty different.
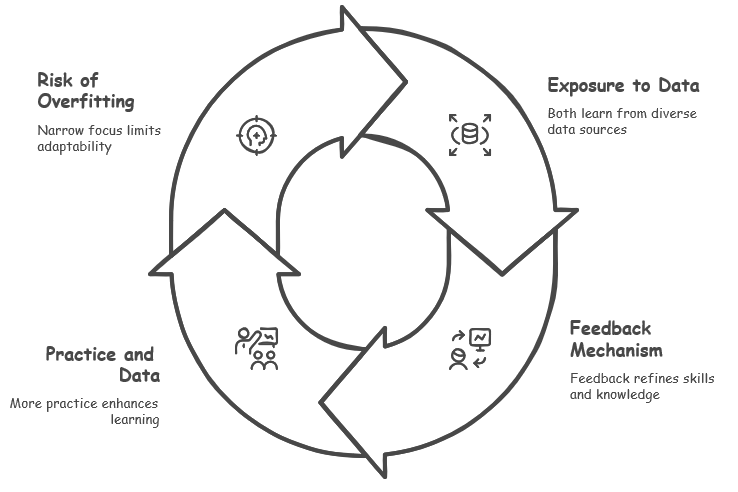
Both learns from training data : Both machine learning systems and humans rely on exposure to specific data or experiences to build their understanding and capabilities. For machines, this might involve datasets filled with labeled examples, while for humans, it could be life experiences, education, or repeated practice. In both cases, the quality, quantity, and relevance of the training data or experiences play a crucial role in shaping the depth and accuracy of what is learned, forming the foundation for future recognition and decision-making.Both seems to be augmented (or reinforced) by some kind of feedback mechanism Just as machines use feedback loops—such as error correction in supervised learning or rewards in reinforcement learning—humans also benefit from feedback to refine their knowledge and skills. A teacher’s correction, a coach’s guidance, or even self-reflection after a mistake can serve as feedback for humans, helping to reinforce correct behaviors or adjust misunderstandings. This iterative process of receiving and incorporating feedback allows both machines and humans to improve over time, fine-tuning their models or mental frameworks to better align with the desired outcomes.The more training data is fed, the better both learn In machine learning, feeding more diverse and extensive datasets typically enhances a model’s performance, enabling it to generalize better across various scenarios—though, as noted, there’s a limit to avoid overfitting. Similarly, humans tend to improve their skills and understanding through repeated exposure and practice. The more a person engages with a subject—whether through reading, practicing, or experiencing—the deeper their mastery becomes. However, just like machines, humans can also become overly specialized or rigid if they focus too narrowly on specific data, potentially missing broader patterns or struggling to adapt to new, unfamiliar situations.Training with only a few limited training data may result in overfitting. This overfitting would degrade the capability of recognizing the new data (the data not used for training). Overfitting in machine learning occurs when a model becomes too tailored to its training data, losing the ability to generalize to new, unseen data, which reduces its effectiveness in real-world applications. In humans, a similar phenomenon can occur when someone becomes overly focused on a narrow set of experiences or knowledge, leading to tunnel vision or an inability to adapt to new contexts. For instance, a student who memorizes specific examples for an exam but fails to grasp underlying concepts may struggle with new problems. In both cases, this limitation highlights the importance of diverse and balanced training or exposure to ensure robust, flexible learning that can handle novel challenges effectively.
Difference between Machine Learning and Human Learning
Depending on how you look at it, machine learning and human learning may seem strikingly similar—as highlighted in the previous section—but their differences reveal unique strengths and challenges that set them apart, offering exciting possibilities for advancing machine learning technology by drawing inspiration from human capabilities. Machines require extensive data preparation and massive amounts of input to learn effectively, while humans can pick up new skills with far less effort and fewer examples, guided by intuition, emotion, and context. These differences highlight unique strengths and limitations in each, offering exciting opportunities for advancing machine learning technology by narrowing the gap with human capabilities.
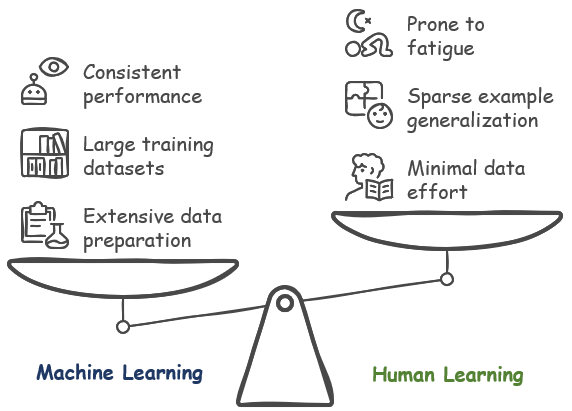
Data Preparation Effort : Unlink Machine Learning requires extensive data preparation process (generating huge cost as well) to feed the data into a specific machine learning algorithm, human brain does not (almost not) require this kind of process. Of course, Human learning also requires some effort for data search (like googling the document or searching video), but this is incomparably small effort comparing to all those data preparation listed in WhatTheyDo. For machines, the process involves cleaning, labeling, and structuring vast amounts of data, often requiring significant computational resources and human oversight, while humans can intuitively gather and process information from their surroundings with minimal preprocessing, relying on natural curiosity and observation.Data Efficiency : Human Brain can learn things with much less number of training data than Machine Learning. Most of machine learning algorithm would require huge set of training data (a few thousands or millions of training data set), but human brain would require much less number of training data. You may learn a new thing to a certain (meaningful) level just by watching several tens of video or blog posts. If we can revolutionize machine learning algorithm so that I can learn to the level of human brain with such a few training data, it can be a great breakthrough. This efficiency stems from the human brain’s ability to generalize from sparse examples, draw on prior knowledge, and make intuitive leaps, whereas machines often need vast datasets to achieve comparable understanding, highlighting a key area for potential advancement in AI.Attention and Fatigue : One of the main advantage of machine learning would be that Machine Learning algorithm gets never tired or lose attention to each and every training input. But think of the situation where you have to watch a long video or watch several video/read the several document back to back. It would be hard for you to maintain the same level of attention throughout all the training process. Machines, on the other hand, can process endless streams of data without fatigue, maintaining consistent performance regardless of the volume or duration of input, while humans naturally experience mental fatigue, distraction, or loss of focus, which can affect learning efficiency over time.Emotional and Contextual Influence : Human learning is deeply influenced by emotions, motivation, and context, which machine learning currently struggles to replicate. A person’s interest in a subject, emotional connections to the material, or the environment in which they learn can significantly impact retention and understanding, whereas machines operate solely on data and predefined rules, lacking the emotional or contextual awareness that drives human learning. Bridging this gap could lead to more adaptive and empathetic AI systems.Speed vs. Creativity : Machine learning can process and analyze data at speeds far beyond human capabilities, but it lacks the creative and intuitive problem-solving that humans excel at. While a machine can crunch numbers and identify patterns in milliseconds, humans can brainstorm novel solutions, think outside the box, and apply abstract reasoning to solve problems, often without explicit training data. Enhancing machine learning to mimic this human creativity could unlock new frontiers in artificial intelligence..