CNN stands for Convolutional Neural Network. It is a special type of Neural Network that have structure as illustrated below. As you see, it is made up of multiple component and the functionality of the first component of the network is Convolution layer. Since the role of this convolution layer is so critical to the functionality of the whole architecture, it is called Convolutional Neural Network(CNN). To understand in more details on how CNN works, you need to understand the meaning of convolution, especially 2D convolution. If you are not familiar with the concept of 2D convolution, read my note on 2D convolution first.
CNN has become one of the most popular neural network since it showed such a great performance on image classification. Most of neural network that is used for image recognition or classification is based on CNN.
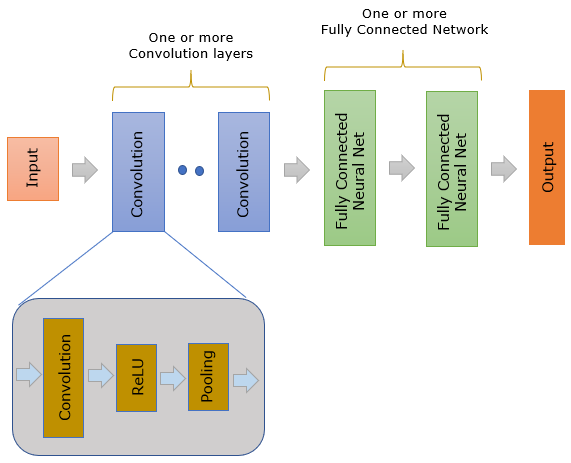
As you see in the illustration above, CNN has made up of two large groups of components :: Convolutional Layer and Fully Connected Network layer. Major functionality of these two components can be summarized as follows. (The role of these two major block is well explained in section II of Ref [6])
If you look a little bit deeper into Convolution layer, it has a few more procedures in addition to convolution as shown above. Almost every CNN, the result of the convolution goes through a special function called ReLU(Rectified Linear Unit). You can think of ReLU as a kind of activation function(transfer function) for Convolution layer. And in many cases the output of ReLU data goes through another process called Pooling. Pooling is a kind of Sampling method to reduce the number of data without loosing the critical nature of the convolved data. I will talk later about the Pooling process.
After the convolution layer in CNN, one or more of fully connected neural network. Fully Connected Network is a simple feedforward network.
More Details
Now let's talk about more details on how CNN works. I think one of the best way to learn on details of CNN is to investigate (study) some famous early models. I strongly recommend you to study the famous model introduced in Ref [6].
One of the difficulties in starting to learn a technology that has been evolved so long (like Machine Learning), it is difficult to find technical material explaining the basic / fundamental principles. In this case I always recommed you to find some old original papers or books in the area and I think Ref [6] can a good one for this. In this section, I would explain the basic principle / structure of CNN based on that document. Of course, I will try to explain in my own words and own style but the main idea is from the original paper. Especially Section II.A. When I say 'the document' in this section, I mean Ref[6] unless I mention it otherwise/
I will take several days for me to complete this section in my free time.
First I labeled each of the steps in the image from the document as follows since there would be many cases where I explain for a specific step of the process.
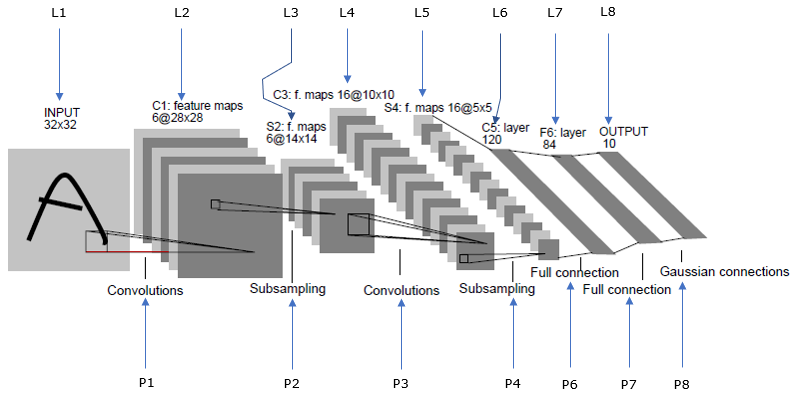
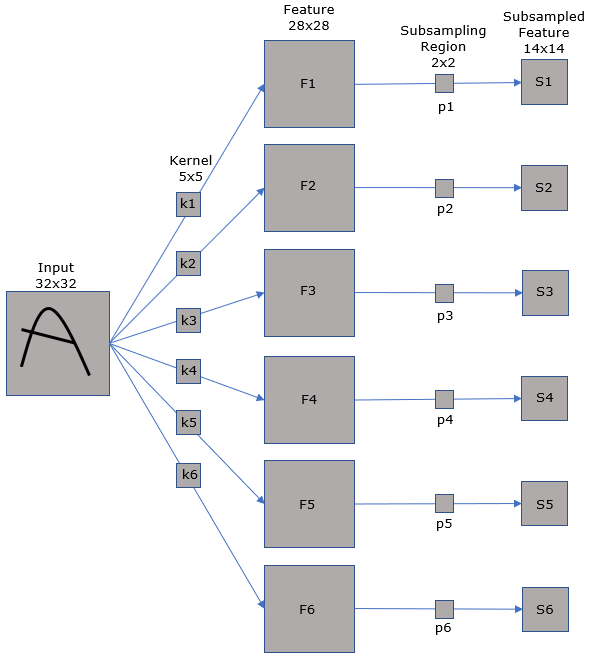
For practice and more attention to the details, try to verbalize this illustration (This is what I often to to study any new technology that I don't have any complete understandings. That is, translate verbal description to figures and describe figure in verbal/written form).
- The layer of input is only one. It implies that the input of this network would require black-and-white or grey scale image.
- The dimension of the input image is 32 x 32 pixels
- The single input layer is convoluted with 6 different kernels with the size of 5x5.
- The result of the convolution with six different Kernels is 6 different 2D data(called Feature) with the size of 28x28. Why the size get different from the input dimension after convolution ? Check your understandings on 2D convolution. Unless you add the padding to the input, the result of convolution gets smaller depending on the size of Kernel. In this case, the size decreased from 32x32 to 28x28 since the kernel size is 5x5.
Long time ago (probably more than 10 years ago) I had some interest in image processing and I did some practice on 2D convolution for various image. At that time, what I tried most often is to make a few predefined kernel (we normally called it a filter) and do convolution and see how the image changes with those filters. When I saw the firs step (L1->P1->L2), a few questions popped up right away in my mind.
The exact functionality of the kernel is not obvious for user (programmer). When I did the convolution for the purpose of image processing, I used some specially designed kernels with explicit functions like edge detection, noise filtering etc. But in CNN, the functionality of each of those kernels are not explicitely defined by user (programmer). Actually the user does not even know the exact functionality of the kernel. User would just know that the kernel would extract some meaningful feature from the input data but doesn't know exactly what kind of feature should be detected. In CNN, the exact type of features to be detected is dermined by the network itself during the learning process.
The element values for each of the kernel does not seems to be fixed/predefined. When I did the convolution for the purpose of image processing, I used some specially designed kernels with all of the element values of the kernel is known/predefined and we(programmer) knows exactly why those elements values are set in that way (like the element values of this kernal is set like this because it is for edge detection or they are set in this way because it is for noise filtering etc), but in CNN those element values are not predefined. It usually set randomly and gets updated (changes) during learning process.
How many Kernel should be used ? (that is, how many different features should be detected). In other words, this is asking 'How many different features do I need to fiind(extract) at this step ?'. However, there is not explicit theoretical answer for this. This is a parameter you (programmer) has to determine when you design a network and it would based more on try-and-see type of process.
Why we need pooling ? There are a few commonly mentioned reason for this. Some people say it is for reducing the number of data. You would see clearly that this would be true since you see the result of the pooling (subsampling) is much smaller than the input in terms of the number of data. There is another reason which may not seem such obvious but can be more fundamental reason for why this step is used. The document says this process (i.e, Pooling/Sub sampling) make the network more robust on scale, shift of the input image.
- A Complete convolutional layer is composed of several feature maps (with different weight vectors), so that multiple features can be exptracted at each location.
- The kernel of the convolution is the set of connection weights used by the units in the feature map.
- An interesting property of convolutional layers is that if the input image is shifted, the feature map output will be shifted by the same amount, but will be left unchanged otherwise. This property is at the basis of the robustness of convolutional networks to shifts and distortions of the input.
- Once a feature has been detected, its exact location becomes less important. Only its approximate position relative to other features is relavant.
- A simple way to reduce the precision with which the position of distinctive features are encoded in a feature map is to reduce the spatial resolution of the feature map. This can be achieved with a so-called sub-sampling layers which performs a local averaging and a sub-sampling, reducing the resolution of the feature map, and reducing the sensitivity of the output to shifts and distortions.
Well Known examples of CNN
There are many well known Neural Network based on CNN which is mainly for image classification. Followings are the summary of the famous CNN based image classifier. You can get more detailed information in reference section.
|
Name |
Input Dimension |
Output |
Number of Parameters |
Year |
| LeNet-5 |
32x32x1 |
10 |
60,000 |
1998 |
| AlexNet |
224x224x3 |
1000 |
60,000,000 |
2012 |
| VGG-16 |
224x224x3 |
1000 |
138,000,000 |
2014 |
| Inception-v1 |
224x224x3 |
1000 |
5,000,000 |
2014 |
| Inception-v3 |
224x224x3 |
1000 |
24,000,000 |
2015 |
| ResNet-50 |
224x224x3 |
1000 |
26,000,000 |
2015 |
| Xception |
299x299x3 |
1000 |
23,000,000 |
2016 |
| Inception-V4 |
299x299x3 |
1000 |
43,000,000 |
2016 |
| Inception-ResNets |
299x299x3 |
1000 |
56,000,000 |
2016 |
| SqueezeNet |
224x224x3 |
1000 |
1,200,000 |
2016 |
| ResNeXt50 |
224x224x3 |
1000 |
25,000,000 |
2017 |
| DenseNet-121 |
224x224x3 |
1000 |
8,000,000 |
2017 |
| MobileNetV2 |
224x224x3 |
1000 |
3,500,000 |
2018 |
How does CNN work so well ?
Suppose that you want to make an algorithm for image recognition with conventional method (i.e, without using CNN). The simplest way you can think of would be to check some characteristics on a specific pixel (or set of pixels). In this case, the algorithm may come up with the completely different result for the same object if the position of the object on the image file changes or size changes or rotated etc. Even if you use more sophisticated statistical method, you still suffer from those geometry changes. However, CNN is so robust for this kind of position, size or rotational changes and it can identify the object only from a part (not the whole) of the object. I think this robustness mainly comes from the convolution. If you are familiar with how 2D convolution works (if you are not familiar with 2D convolution, try with my other notes mentioned at the beginning), you may guess how 2D convolution can provide such a robustness. In 2D convolution, the kernel/filter represents a certain feature of the object. The filter scans across the whole picture bit by bit. So even if a specific feature of the object in the image change position, size or rotation they can be detected by the scanning filters during the convolution process.
Just for fun (also for study), I tried with google image search (image.google.com). I tried searching with the following 4 images and you see Google Image Search comes up with some kind of 'elephant' for all of the image that I used. You would see the search engine recognize the image pretty well regardless of size, part or whole, rotation etc. CNN is a critical component of Google Image Search (If you are interested further details, refer to Ref [5]).
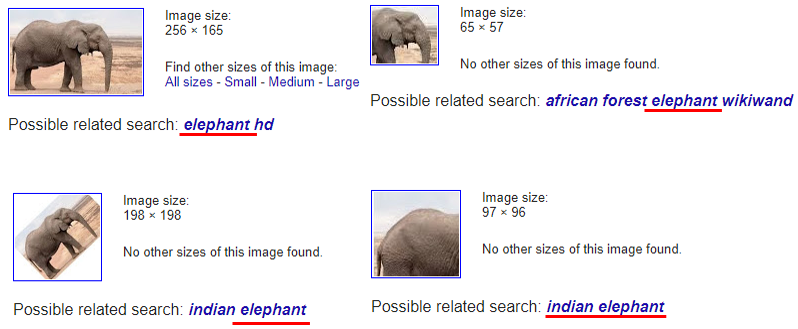
The first two (top left and top right) gives other images with elephant or part of elephant in it, but the other two (bottom left and bottom right) gives completely different result as shown below.
Try with your own images and check how it works. You would see both the strengh and weakness of one of the most advanced Deep Learning algorithm. ==> This search was done in Jan 2020 and I think the result would be much better and realistic if you try the same thing now.


Reference :
[1] Illustrated: 10 CNN Architectures (2019)
[3] Common architectures in convolutional neural networks.(2018)
[4] A Survey of the Recent Architectures of Deep Convolutional Neural Networks
[5] Building an image search service from scratch
[6] Gradient-Based Learning Applied to Document Recognition (1998)
YouTube :
- The moment we stopped understanding AI [AlexNet] - Welch Labs (2024)